Python 自动爬取花瓣网任意面板中所有图片
注:该项目只适用于旧版花瓣,但其中的思路值得领会。对于新版花瓣编写的代码,逻辑差别不大。
需要安装的库
- urllib
- easygui
- selenium
- webdriver_manager
获取过程
- 进入面板内
- 复制当前面板 url
- 启动该脚本按提示进行即可
代码编写流程
分析 pin 图特点
查看面板源码,可以在对应的 script 中找到面板中图片的 json 数据。
在 app.page[“board”] 下可以找到 “pins”:[{…}],主要图片 ID(pin) 位于这里面。
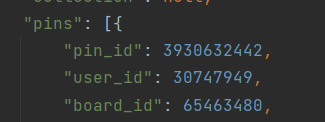
获取到图片的 ID(pin) 之后可以对应访问点击图片后进入的地址 http://huaban.com/pins/pinId/,并获取页面源码:
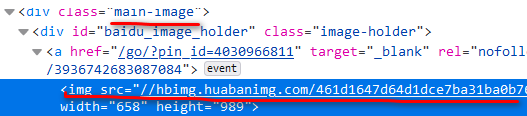
显然可见主要图片的源码特征,书写对应正则表达式可以获取图片真实地址。
分析滚动特点
通过滚动页面我们可以发现加载规律:
原来的图片对应的代码:
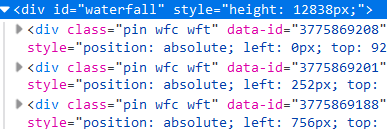
经过滚动,原来的代码逐渐被一些新的代码取代:
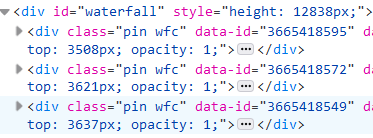
而不难发现他们都有对应的data-id!而 data-id 就是图片地址中对应的 pin。
所以我们可以通过 webdriver 滚动加载页面,每滚动一次就进行一次 data-id 的读取,并利用集合进行去重即可。
具体实现
1# 花瓣用户任意面板图片爬取
2import urllib.request
3import urllib.error
4import re
5import os
6import datetime
7import easygui
8import time
9from selenium import webdriver
10from selenium.webdriver.chrome.service import Service
11from selenium.webdriver.common import service
12from webdriver_manager import driver
13from webdriver_manager.chrome import ChromeDriverManager
14import winsound
15
16# 获取网页中所有图片对应的pin
17def get_pins(url_, num_):
18 my_options = webdriver.ChromeOptions()
19 my_options.add_argument("start-maximized")
20 my_options.add_argument("--ignore-certificate-errors")
21 my_options.add_argument("--ignore-ssl-errors")
22 my_options.add_experimental_option("excludeSwitches", ['enable-automation', 'enable-logging'])
23 driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=my_options)
24 # 如果当前chromedriver版本不对,会自动去官网下载对应的版本到~/.wdm/drivers/chromedriver里,且会有缓存,下次直接读取缓存
25 driver.get(url_)
26
27 js = "window.scrollTo(0,document.body.scrollHeight);" # js脚本实现向下滑动
28 pattern = re.compile(r'data-id=?"(\d*)"')
29 pins_ = set()
30 # 可以使用大括号 { } 或者 set() 函数创建集合,但是注意如果创建一个空集合必须用 set() 而不是 { },因为{}是用来表示空字典类型的。
31 num = int(num_)
32 tries = num / 15 + 1; # 滑动次数,每次滑动大约可以获得15张图片的pin
33 while True:
34 tries -= 1
35 html_ = driver.page_source
36 pins_1 = re.findall(pattern, html_) # 返回获取到的pin列表
37 pins_2 = set(pins_1) # pin列表转化为pin集合
38 pins_.update(pins_2) # 求交集,以免下载重复照片
39 driver.execute_script(js)
40 time.sleep(1) # 给脚本运行留足时间
41 if tries < 0:
42 break
43 driver.close()
44 return pins_
45
46
47# 获取页面html
48def get_html_1(url_):
49 try:
50 page = urllib.request.urlopen(url_)
51 except urllib.error.URLError:
52 return 'fail'
53 html_ = page.read().decode('utf-8')
54 return html_
55
56
57# 下载图片
58def get_image(path_, pin_list):
59 success = 0
60 fail = 0
61 now = time.time()
62 t_now = time.strftime("%Y-%m-%d_%H-%M-%S_", time.localtime(now))
63 for pinId in pin_list:
64 # 获取跳转网页网址
65 url_str = r'http://huaban.com/pins/%s/' % pinId
66
67 # 获取点击图片时弹出网页的源码
68 pinId_source = get_html_1(url_str)
69 if pinId_source == 'fail':
70 continue
71
72 # 解析源码,获取原图片的网址
73 '''
74 <div class="main-image"><div class="image-holder" id="baidu_image_holder">
75 <img src="//hbimg.huabanimg.com/64369267b9c8dc7a43da81457658c05b1a752f9329ec0-dSfdfl_fw658/format/webp"
76 '''
77 img_url_re = re.compile('main-image.*?src="(.*?)"', re.S)
78 img_url_list = re.findall(img_url_re, pinId_source)
79 img_url = 'http:' + img_url_list[0]
80 try:
81 urllib.request.urlretrieve(img_url, path_ + "\\" + t_now + str(success) + ".jpg")
82 # urlretrieve()方法直接将远程数据下载到本地
83 except urllib.error.URLError:
84 print("获取失败!%s" % img_url)
85 fail += 1
86 continue
87 print("获取成功!%s" % img_url)
88 success += 1
89 print("成功获取图片张数:%d" %success)
90 print("获取失败的图片张数:%d" %fail)
91 winsound.Beep(frequency=250, duration=500)
92 os.system("pause")
93
94
95# 创建文件夹路径
96def createPath():
97 while True:
98 path_ = easygui.diropenbox(title='选择你要保存的路径')
99 filePath = path_ + "\\" + str(datetime.datetime.now().strftime('%Y-%m-%d %H.%M.%S'))
100
101 isExists = os.path.exists(filePath)
102 if not isExists:
103 # 创建目录
104 os.makedirs(filePath)
105 print('%s创建成功!' % filePath)
106 break
107 else:
108 print('%s已存在重新输入!' % filePath)
109 return filePath
110
111
112if __name__ == '__main__':
113 # 用户输入数据
114 values = easygui.multenterbox("获取花瓣用户任意面板中的图片", "welcome", ["面板的地址", "想下载的大概张数"])
115 url = values[0]
116 num = values[1]
117 path = createPath()
118
119 # 获取图片的pin
120 pins = get_pins(url, num)
121
122 # 获取并下载图片
123 print('即将为主人下载%d张照片~' %len(pins))
124 get_image(path, pins)