数据库重要知识整理汇总
TOC
关系数据库理论
关系数据库理论为关系数据库的设计和实现提供了理论基础和指导原则。
关系语言的种类
- 关系代数
- 关系演算(元组演算和域演算)
- SQL
关系的定义
- 候选码 (Candidate Key):能唯一标识元组的属性(组)。
- 主码 (Primary Key):多个候选码中选定一个作主码。
- 主属性 (Prime Attribute):候选码中的诸属性。
- 非主属性 (Non-Key Attribute):不出现在任何候选码中的属性。
关系运算
5 种基本关系代数运算:
- 并 ($\cup$)
- 差 ($-$)
- 投影 ($\pi$): 从某个关系中选择出若干属性列组成新的关系
- 选择 ($\sigma$): 在某个关系中选择满足给定条件的诸元组
- 笛卡尔积 ($\times$)
其它运算:
- 连接 ($\bowtie$): 从两个关系的笛卡尔积中选取属性间满足一定条件的元组
- 除 ($\div$): 设关系 R 除以关系 S 的结果为关系 T,则 T 包含所有在 R 但不在 S 中的属性及其值,且 T 的元组与 S 的元组的所有组合都在 R 中
- 重命名 ($\rho$): 将某个关系重命名为其它关系名
关系演算
关系演算就是用谓词来描述关系的构成(查询的结果)。按照谓词变元的不同分为元组关系演算和域关系演算,分别简称为元组演算和域演算。
元组演算例子
给出关系模式:
- S (Sno, Sname, Ssex, Sage, Sdep)
- C (Cno, Cname, Ccredit, Cpno)
- SC (Sno, Cno, Grade)
查询选修学号为“95002”的学生所选全部课程的学生学号。
$\{ t|\exists u(SC(u) \land \forall v(SC(v) \land v['Sno']='95002' \rightarrow \exists w(SC(w) \land w['Sno']=u['Sno'] \land w['Cno']=v['Cno'])) \land t['Sno']=u['Sno']) \}$
域演算例子
同上关系模式,查询选修了 C2 课程的学生学号和成绩。
$\{t_1, t_2 | \exists u_1 \exists u_2 \exists u_3 (SC(u_1, u_2, u_3) \land u_2='c2' \land t_1=u_1 \land t_2=u_3)\}$
or
$\{t_1, t_2 | SC(t_1, 'C2', t_2)\}$
范式
数据库范式是用于规范化数据库表结构的规则,旨在减少冗余和提高数据完整性。下面具体介绍这几个范式。
- BCNF: 关系模式 $R \in 3NF$,且对于 R 的每个函数依赖 $X \rightarrow Y (Y \nsubseteq X)$,X 必包含码
第一范式(1NF)
- 定义:关系模式 R 的所有属性都是不可分的基本数据项。即表中的每个字段都必须是原子的,即每个字段只能包含单一值,不能有重复的行。
- 目的:消除重复组,确保数据的原子性。
- 示例:如果一个表中有一个字段存储多个电话号码,需要将其拆分成多个独立的记录。
第二范式(2NF)
- 定义:关系模式 $R \in 1NF$,且每一个非主属性都完全函数依赖于 R 的码(而不是部分依赖)。即在满足 1NF 的基础上,表中的每个非主属性必须完全依赖于候选键的整个组成部分,而不是部分依赖。
- 目的:消除部分依赖,确保所有非主属性完全依赖于主键。
- 示例:如果一个表的主键由两个字段组成,而一个非主属性只依赖于其中一个字段,就需要将其分拆成两个表。
第三范式(3NF)
- 定义:关系模式 $R \in 2NF$,且不存在非主属性对码的传递依赖。即在满足 2NF 的基础上,表中的每个非主属性必须直接依赖于候选键,而不是通过其他非主属性间接依赖(即消除传递依赖)。
- 目的:消除传递依赖,确保非主属性仅依赖于主键。
- 示例:如果一个表主键为 AB,AB → C,但存在 A → B 和 B → C 的依赖关系,需要将其分拆成两个表,以消除 B → C 的传递依赖。
巴斯-科德范式(BCNF)
- 定义:在满足 3NF 的基础上,表中的每个决定因素都必须是候选键。
- 目的:进一步消除依赖异常,确保所有决定因素都是候选键。
- 示例:如果一个表中存在非主属性对主属性的依赖关系,需要将其分拆,以确保每个决定因素都是候选键。
通过遵循这些范式,可以设计出结构良好的数据库,提高数据的完整性和一致性。
数据库授权
将数据库中的某些对象的某些操作权限赋予某些用户
1GRANT <权限>[,<权限>]...
2 [ON <对象类型> <对象名>]
3 TO <用户>[,<用户>]...
4 [WITH GRANT OPTION];
指定了 WITH GRANT OPTION 子句, 获得某种权限的用户还可以把这种权限再授予别的用户。
一些例子:
1GRANT ALL PRIVILIGES /* 所有权限 */
2ON TABLE Student, Course
3TO U2, U3
4WITH GRANT OPTION;
5
6GRANT SELECT
7ON TABLE SC
8TO PUBLIC; /* 所有用户 */
9
10GRANT UPDATE (Sno), SELECT
11ON TABLE Student
12TO U4;
从指定用户那里收回对指定对象的指定权限:
1REVOKE <权限>[,<权限>]...
2[ON <对象类型> <对象名>]
3FROM <用户>[,<用户>]...;
存储过程及触发器
存储过程
存储过程(Stored Procedure) 是一组为了完成特定功能的 SQL 语句集,经编译后存储在服务器端数据库中,用户通过指定存储过程的名字并给定参数(如果该存储过程带有参数)来执行它。
1CREATE [ OR ALTER ] { PROC | PROCEDURE }
2 [schema_name.] procedure_name [ ; number ]
3 [ { @parameter_name [ type_schema_name. ] data_type }
4 [ VARYING ] [ NULL ] [ = default ] [ OUT | OUTPUT] | [READONLY]
5 ] [ ,...n ]
6[ WITH <procedure_option> [ ,...n ] ]
7[ FOR REPLICATION ]
8AS { [ BEGIN ] sql_statement [;] [ ...n ] [ END ] }
9[;]
10
11<procedure_option> ::=
12 [ ENCRYPTION ]
13 [ RECOMPILE ]
14 [ EXECUTE AS Clause ]
一个例子:
1USE pubs
2GO
3if exists (SELECT name FROM sysobjects
4 WHERE name = 'titles_sum' AND type = 'p ')
5 DROP PROCEDURE titles_sum
6
7GO
8CREATE PROCEDURE titles_sum @stor_id char(4), @sum smallint
9OUTPUT AS
10 SELECT ord_num, ord_date, payterms, title_id, qty
11 FROM sales
12 WHERE stor_id = @stor_id
13 SELECT @sum = sum (qty)
14 FROM sales
15 WHERE stor_id = @stor_id
16 Return (0)
17GO
触发器
触发器是一种特殊类型的存储过程。它与存储过程的区别:触发器主要是通过事件进行触发而被执行的,而存储过程可以通过存储过程名字被直接调用执行。
当对某一表进行诸如 UPDATE、 INSERT、DELETE 这些操作时,SQL Server 就会自动执行触发器所定义的 SQL 语句。
1CREATE [ OR ALTER ] TRIGGER [ schema_name . ]trigger_name
2ON { table | view }
3[ WITH <dml_trigger_option> [ ,...n ] ]
4{ FOR | AFTER | INSTEAD OF }
5{ [ INSERT ] [ , ] [ UPDATE ] [ , ] [ DELETE ] }
6[ WITH APPEND ]
7[ NOT FOR REPLICATION ]
8AS { sql_statement [ ; ] [ ,...n ] | EXTERNAL NAME <method specifier [ ; ] > }
9
10<dml_trigger_option> ::=
11 [ ENCRYPTION ]
12 [ EXECUTE AS Clause ]
13
14<method_specifier> ::=
15 assembly_name.class_name.method_name
一个例子:
1CREATE TRIGGER utitle1 ON titles
2FOR UPDATE
3AS
4declare @rows int
5SELECT @rows=@@rowcount
6if @rows=0
7 RETURN
8if UPDATE (title_id)
9BEGIN
10 if @rows > 1
11 BEGIN
12 raiserror( 'update to primary keys of multiple row is not permitted' , \\
13 16,10)
14 ROLLBACK TRANSACTION
15 RETURN
16 END
17 UPDATE t SET t.title_id=i.title_id
18 FROM titleauthor t, inserted i, deleted d
19 WHERE t.title_id=d.title_id
20END
21RETURN
原理解析:
在触发器的执行过程中,系统会自动建立和管理两个逻辑表:插入表(inserted)和删除表(deleted)。
这两个表与触发器所对应的基本表有着完全相同的结构,但为只读表,驻留于内存之中,直到触发器执行完毕,系统会自动删除。
这两个表是事务回滚的重要依据。
数据库事务
事务 (Transaction) 是用户定义的一个数据库操作序列,这些操作要么全做,要么全不做,是一个不可分割的工作单位。
ACID 特性
- 原子性(Atomicity):事务中包括的诸操作要么都做,要么都不做。
- 一致性(Consistency):事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。
- 隔离性(Isolation):一个事务的执行不能被其他事务干扰,而影响它对数据的正确使用和修改。
- 持久性(Durability):一个事务一旦提交,它对数据库中数据的改变就应该是永久性的,接下来的其他操作或故障不应该对其执行结果有任何影响。
并发导致的问题
- 丢失修改:当两个事务并发执行但没有锁的控制,可能导致其中一个事务的处理结果被覆盖
- 脏读:某一事务发生回滚,另一事务读到的数据和数据库中的不一致
- 不可重复读:某一事务修改了数据,可能导致另一事务中前后读取到的数据不一致
- 幻读:某一事务插入或删除了部分记录,另一事务前后读取数据发现记录多或少了
四个隔离级别
- 读未提交:允许读到未提交的事务,解决了丢失修改问题。
一个事务读的时候允许其他事务操作,写的时候其他事务只能读不能写。
- 读已提交:只允许读已提交的事务,再解决了脏读问题。(PostgreSQL 默认隔离级别)
一个事务读的时候允许其他事务操作,写事务的时候禁止其他任何事务。
- 可重复读:再解决了不可重复读问题。(MySQL 默认隔离级别)
一个事务读取的时候其他事务不可修改(允许读),写事务的时候禁止其他任何事务。
- 串行化:再解决了幻读问题。
事务串行化执行,使用表级锁。
MVCC 多版本并发控制
MVCC, Multiversion Concurrency Control, 多版本并发控制,解决读写并发问题。
没有写的情况下发读-读并发是不会出现问题的,而写-写并发这种情况比较常用的就是通过加锁的方式实现。那么,读-写并发则可以通过 MVCC 的机制解决,它可通过无锁的方案来实现并发控制。
首先我们需要理解快照读和当前读,普通的 select 语句在加锁的情况下(for update)就是当前读,反之即快照读,而快照即是 UndoLog 中所记录的更新前的数据。当存在多个快照时,要读哪个呢,这时我们需要知道快照的存储方式。
数据库中的每行记录都存在着隐式字段:隐藏主键,对这条记录做了最新一次修改的事务 ID,以及回滚指针,它指向这条记录的上一个版本,即 UndoLog 中的上一个版本的快照的地址。当发生数据更新时,将会将当前行记录存为一个快照,当有多个快照时,多个快照将会通过回滚指针连成一个链表。
有了快照链表的概念,我们还需理解 ReadView,数据库通过它来决定快照链表中哪条记录是可见的,即会被某个 select 查出。不同隔离级别下,ReadView 的产生有差异。在读已提交隔离级别下,每一条 SELECT 都重新构建一个 ReadView,可以看到其他已经提交的事务对数据的修改,只要事务产生了,其结果都可见,与事务开始的先后顺序无关,也因此无法解决不可重复读的问题。而在可重复读隔离级别下,由第一条 SELECT 生成 ReadView,以后的 SELECT 将复用该 ReadView,这时只有已完成事务的修改可见,即在事务内部不会出现不一致的问题。
那么回到 MVCC,InnoDB 中的 MVCC 就是通过 ReadView + Undolog 来实现的。举个例子,当某个时刻只存在两个事务,一个写操作,一个读操作,这时读写均无需加锁,读操作直接根据 Read View 拿到合适的快照,而写操作直接写并且记录快照即可。
总的来讲,MVCC 是一种作用于读写并发时的无锁并发控制方案,通过 ReadView + Undolog 来实现,读写并发时读操作读 ReadView,写操作写 UndoLog 形成快照链表,此外,MVCC 在 Innodb 中是默认开启的。
注意,快照读的存在,使得读取数据不需要加锁,提高了读操作的性能,但这也意味着数据有可能是历史版本的,是弱一致的,如果同一事务中后续存在 Update 操作,并且基于本次读出来的数据,那么 Update 写入的数据实际上是错误的。
对于这类场景,可以通过在业务上使用乐观锁,在每条记录增加一个版本号字段,每次更新前比对,也可以手动加锁(悲观锁),将快照读升级为当前读:
1SELECT * FROM table WHERE id = 1 lock in share mode -- 加读锁
2SELECT * FROM table WHERE id = 1 for update -- 加写锁
对于 for update, 它会锁定行或者表,上的是排他锁,不同情况锁的行会有差异:
- 当 for update 的字段为索引或者主键的时候,锁住索引或者主键对应的行
- 当没有匹配的行,则无锁
- 除此之外,则上表锁
如果出现无锁,innodb 将通过间隙锁解决 Insert + Update 并发问题。
2PL 两阶段锁
2PL 是数据库事务处理时的并发控制方法,以保证可串行化,解决写写并发问题。
操作数据必须读取当前版本数据的,叫做当前读,包括显式加锁的 SELECT 和隐式加写锁的 INSERT、UPDATE、DELETE。
在 2PL 的加锁阶段,只允许加锁操作,已有读锁可以加读锁但不能再加写锁,已有写锁则不能再加任何锁,无法获取锁的事务只能阻塞等待,直到持锁事务在解锁阶段(事务提交)释放锁后才能继续竞争锁并执行。
间隙锁
事务 A 加行锁 update 某个范围的数据后,事务 B 在这个范围内插入一条记录,这时事务 A 发现多了一条数据,而且没有被自己 update。
MySQL 的实现中,利用了间隙锁在一定索引区间内加锁,锁住甚至不需要的数据,防止其他事务往其中插入数据,这样行锁+间隙锁组成的 Next-Key 锁 就同时防止别的事务修改、删除和插入,解决了幻读的问题。
数据库设计
数据库设计是指对于一个给定的应用环境,构造最优的数据库模式,建立数据库及其应用系统,使之能够有效地存储数据,满足各种用户的应用需求(信息要求和处理要求)。
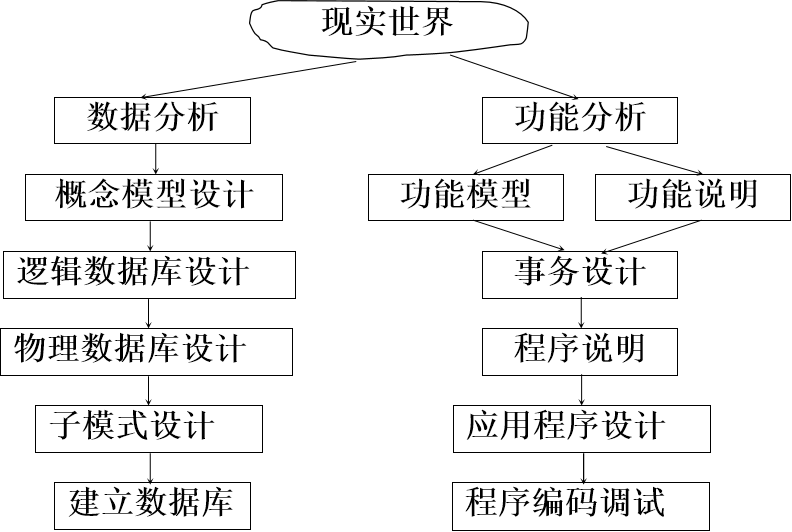
需求分析
需求分析就是通过详细调查现实世界要处理的对象(现实业务),充分了解原系统(手工系统或计算机系统),明确用户的各种需求,并在此基础上确定新系统的功能。需求分析包括两个步骤:需求信息的收集和分析。
需求信息的收集又称为系统调查,即了解用户的组织机构设置、主要业务活动和职能,以及对新系统的要求。
需求信息的分析就是对收集到的需求信息进行加工整理,以数据流图和数据字典的形式进行描述,作为需求分析阶段的成果,这也是下一步设计的基础。
概念模型设计
概念结构设计就是将现实事物以不依赖于任何数据模型的方式加以描述,目的在于以符号化的形式正确地反映现实事物及事物与事物之间的联系。
概念结构设计的内容就是建立概念模型。
这是一个通过 E-R 图构建概念模型的例子:
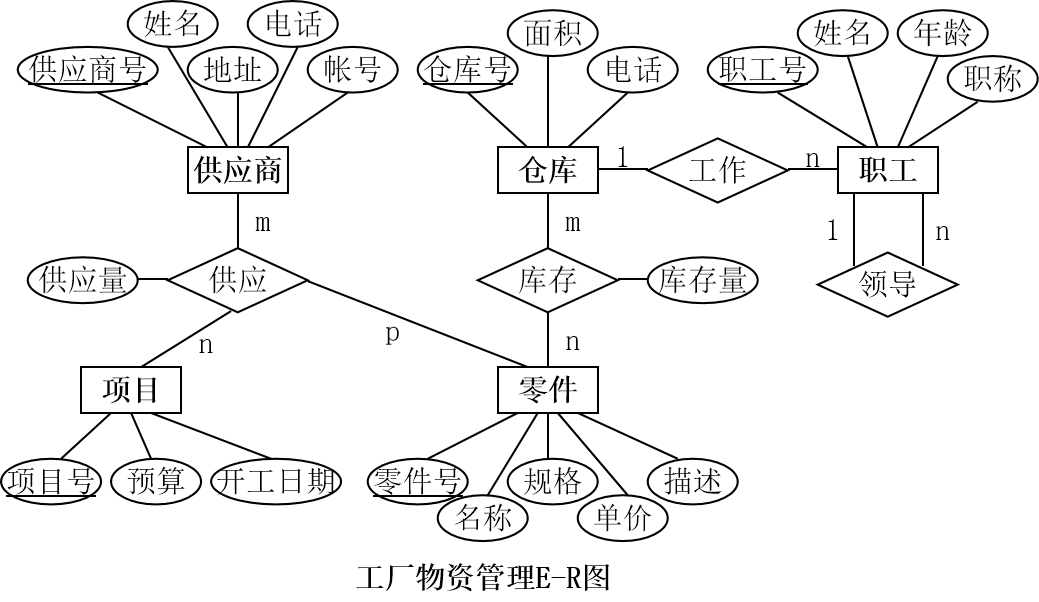
E-R 图三要素:实体,属性,联系。
逻辑结构设计
逻辑结构设计是对数据在计算机中的组织形式的设计,即依照 DBMS 支持的数据模型,设计用户数据的组织形式(模式设计)。同样,逻辑结构设计也是建立在概念结构设计的基础上,为下一步数据的存储设计(物理设计)作准备。
数据库恢复技术
恢复操作的基本原理是冗余,即利用存储在系统其它地方的冗余数据来重建数据库中已被破坏或不正确的那部分数据。
故障种类
- 事务故障:某个事务在运行过程中,由于种种原因未运行至正常,终止点就夭折了
- 系统故障:整个系统的正常运行突然被破坏,所有正在运行的事务都非正常终止,内存中数据库缓冲区的信息全部丢失,外部存储设备上的数据未受影响
- 介质(硬件)故障:存储数据库的设备(如硬盘)发生故障,使存储在其上的数据部分丢失或全部丢失
数据转储(backup)
转储是指 DBA 将整个数据库复制到磁带或另一个磁盘上保存起来的过程。 这些备用的数据文本称为后备副本或后援副本。
转储操作的分类:
- 静态转储:在系统中无运行事务时进行转储,转储开始时数据库处于一致性状态,转储期间不允许对数据库的任何存取、修改活动。
- 动态转储:转储操作与用户事务并发进行,转储期间允许对数据库进行存取或修改。
- 海量转储:每次转储全部数据库。
- 增量转储: 只转储上次转储后更新过的数据。
登记日志文件(logging)
日志文件(log)是用来记录事务对数据库的更新操作的文件。
日志文件的格式及内容:
- 以记录为单位的日志文件
- 各个事务的开始标记(BEGIN TRANSACTION)
- 各个事务的结束标记(COMMIT或ROLLBACK)
- 各个事务的所有更新操作
- 与事务有关的内部更新操作
- 以数据块为单位的日志文件
- 事务标识
- 操作类型(插入、删除或修改)
- 操作对象(记录ID、Block NO.)
- 更新前数据的旧值(对插入操作而言,此项为空值)
- 更新后数据的新值(对删除操作而言, 此项为空值)
恢复策略
数据恢复就是在发生故障、数据被破坏时,根据后被副本和事务日志文件,将数据库恢复到故障前的正确状态(一致性状态)。
根据故障各类的不同,有不同的恢复方法:
- 事务故障:由恢复子系统应利用日志文件撤消(UNDO)此事务已对数据库进行的修改。
- 系统故障:Undo 故障发生时未完成的事务,Redo 已完成的事务。
- 介质故障:重装数据库,使数据库恢复到一致性状态,重做已完成的事务。
数据库 SQL 操作
表连接
1SELECT [ ALL | DISTINCT ] <目标列表达式1> [, <目标列表达式2>] …
2FROM <table_source1>
3-- 不指定则默认使用内连接
4INNER|{LEFT | RIGHT | FULL [OUTER]} JOIN <table_source2>
5ON <search_condition >
6[ WHERE <条件表达式> ]
- [INNER] JOIN 内连接:普通连接操作只输出满足连接条件的元组
- LEFT [OUTER] JOIN 左外连接(⟕):左表为主体,连接条件右边出现空行
- RIGHT [OUTER] JOIN 右外连接(⟖):右表为主体,连接条件左边出现空行
- FULL [OUTER] JOIN 左右外连接(全外连接,⟗):在连接条件的左右两边出现空行
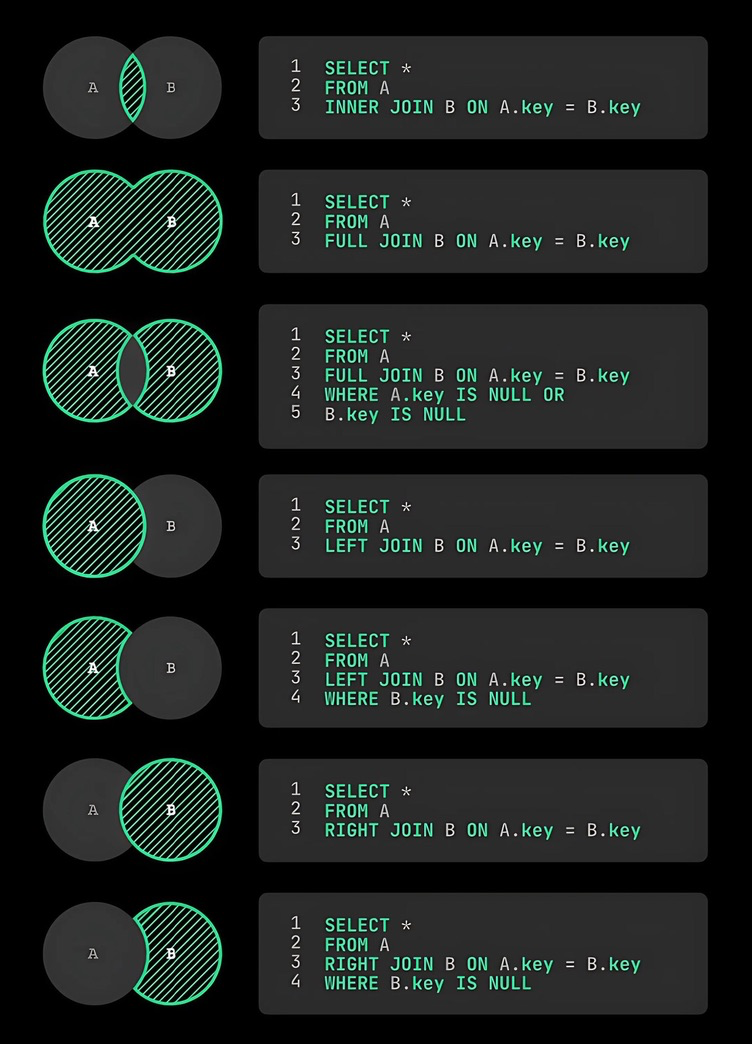
外连接与内连接的区别:普通连接操作只输出满足连接条件的元组,外连接操作以指定表为连接主体,将主体表中不满足连接条件的元组一并输出。
“左”外连接,即以“左”表为主表。
查询操作
MySQL 执行一条 SELECT 语句的流程大致如下:

数据库日志
以 MySQL 为例,日志分类如下:
- 错误日志:记录 MySQL 启动、运行和停止时的错误信息
- 查询日志:记录所有的 SQL 查询,包括连接和断开连接的信息
- 慢查询日志:记录执行时间超过指定阈值的查询,用于性能调优
- 事务日志(RedoLog、UndoLog)
- 二进制日志(BinLog)
RedoLog
RedoLog,即重做日志,是物理日志, 记录内容是“在某个数据页上做了什么修改”, 记录的是物理数据页面修改的信息, 其 RedoLog 是顺序写入 RedoLogFile 物理文件中去的。
RedoLog 是 InnoDB 存储引擎独有的,它让 MySQL 拥有了崩溃恢复能力:
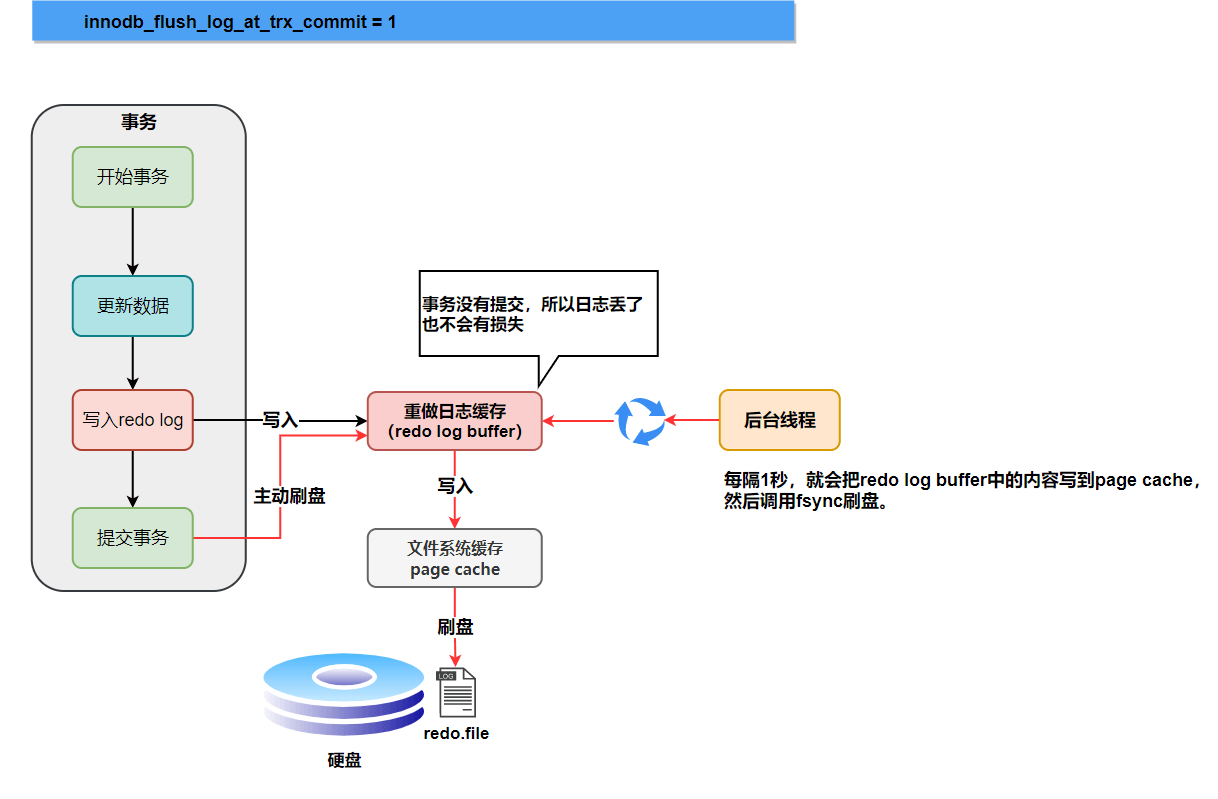
当 innodb_flush_log_at_trx_commit == 1 时, 会进行主动进行刷盘;当为 0 时不会主动进行刷盘, 如果 MySQL 挂了或宕机可能会有 1 秒数据的丢失;当为 2 时, 只要事务提交成功,RedoLogBuffer 中的内容只写入文件系统缓存, 如果仅仅只是 MySQL 挂了不会有任何数据丢失,但是宕机可能会有 1 秒数据的丢失。
UndoLog
UndoLog,即回滚日志,记录数据修改之前的原始值(即“前镜像”),所有事务进行的修改都会先记录到这个回滚日志中,然后再执行相关的操作。
我们知道如果想要保证事务的原子性,就需要在异常发生时,对已经执行的操作进行回滚,在 MySQL 中,恢复机制是通过回滚日志实现的。
如果执行过程中遇到异常的话,我们直接利用回滚日志中的信息将数据回滚到修改之前的样子。并且,回滚日志会先于数据持久化到磁盘上。这样就保证了即使遇到数据库突然宕机等情况,当用户再次启动数据库的时候,数据库还能够通过查询回滚日志来回滚将之前未完成的事务。
BinLog
BinLog 是逻辑日志, 记录内容是语句的原始逻辑, 类似于 “给 ID=2 这一行的 c 字段加 1”, 属于 MySQL Server 层。不管用什么存储引擎, 只要发生了表数据更新, 都会产生 BinLog 日志。MySQL 数据库的数据备份、主备、主主、主从模式 都离不开 BinLog,需要依靠 BinLog 来同步数据,保证数据一致性。
BinLog 的写入时机也非常简单,事务执行过程中,先把日志写到 BinLog Cache,事务提交的时候,再把 BinLog Cache 写到 BinLog 文件中。因为一个事务的 BinLog 不能被拆开,无论这个事务多大,也要确保一次性写入,所以系统会给每个线程分配一个块内存作为 BinLog Cache。
我们可以通过 BinLog_cache_size 参数控制单个线程 BinLog cache 大小,如果存储内容超过了这个参数,就要暂存到磁盘(Swap)。
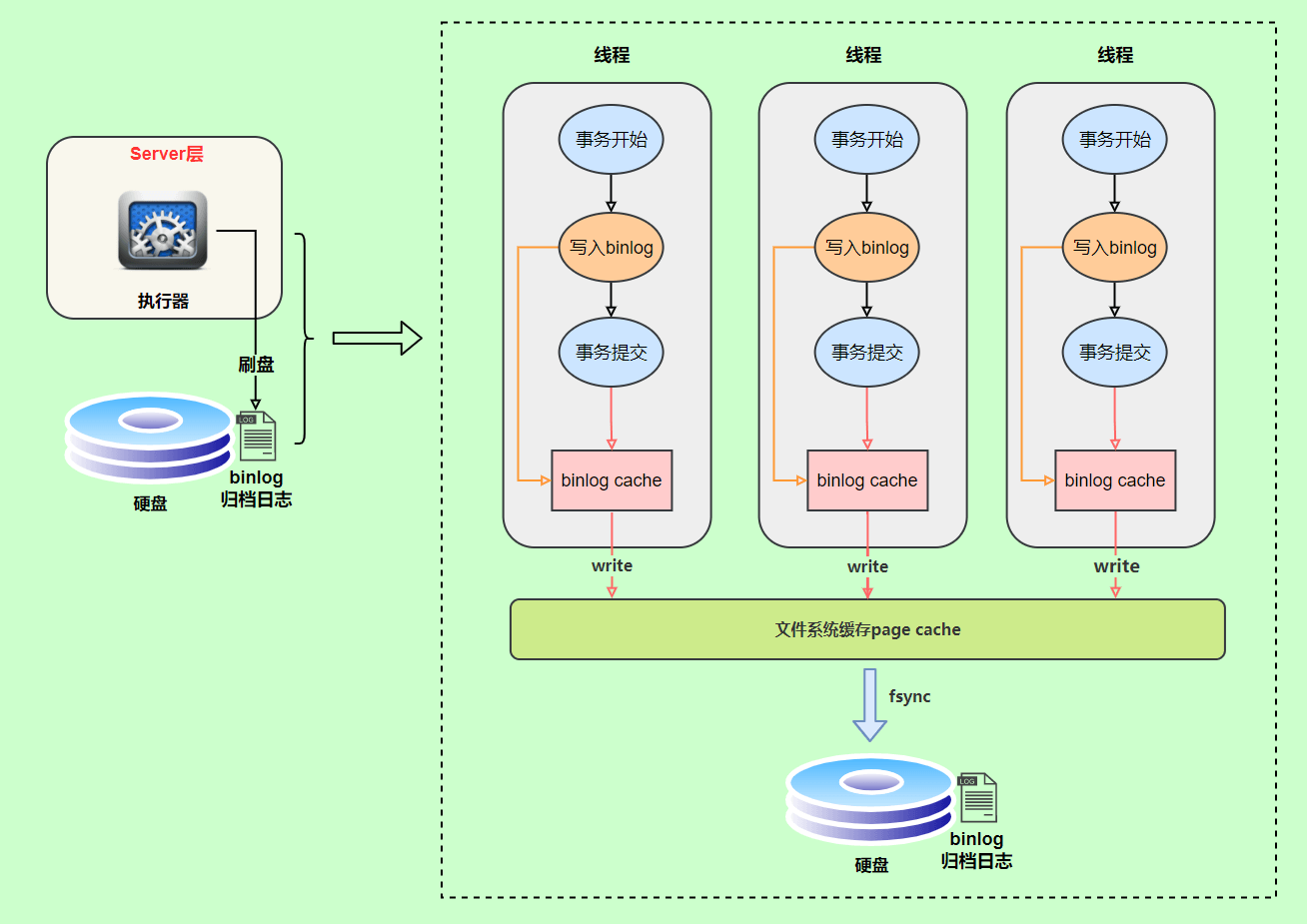
上图的 write,是指把日志写入到文件系统的 page cache,并没有把数据持久化到磁盘,所以速度比较快。上图的 fsync 才是将数据持久化到磁盘的操作。 write 和 fsync 的时机可以由参数 sync_binLog 控制,默认是 1。sync_binLog 为 0 的时候,表示每次提交事务都只 write,由系统自行判断什么时候执行 fsync。虽然性能得到提升,但是机器宕机,page cache 里面的 BinLog 会丢失。为了安全起见,可以设置为 1,表示每次提交事务都会执行 fsync,就如同 RedoLog 日志刷盘流程 一样。
最后还有一种折中方式,可以设置为N(N>1),表示每次提交事务都 write,但累积 N 个事务后才 fsync。
BinLog 和 RedoLog 的一致性
RedoLog 两阶段提交原理?
首先需要了解 RedoLog 两阶段提交原理,其实就是把 RedoLog 的写入拆分成了两个步骤:prepare 和 commit。
SQL 更新语句执行顺序如下:
- 首先,存储引擎将执行更新好的新数据存到内存中,同时将这个更新操作记录到 RedoLog 里面,此时 RedoLog 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
- 然后执行器生成这个操作的 BinLog,并把 BinLog 写入磁盘。
- 最后执行器调用存储引擎的提交事务接口,存储引擎把刚刚写入的 RedoLog 状态改成 commit 状态,更新完成。
崩溃发生点及其相应造成的结果:
p1: 如果数据库在写入 RedoLog(prepare) 阶段之后、写入 BinLog 之前,发生了崩溃:
此时 RedoLog 里面的事务处于 prepare 状态,BinLog 还没写,之后从库进行同步的时候,无法执行这个操作,但是实际上主库已经完成了这个操作,所以为了主备一致,MySQL 崩溃时会在主库上回滚这个事务。
p2: 如果数据库在写入 BinLog 之后,RedoLog 状态修改为 commit 前发生崩溃:
此时 RedoLog 里面的事务仍然是 prepare 状态,BinLog 存在并完整,这样之后就会被从库同步过去,但是实际上主库并没有完成这个操作,所以为了主备一致,即使在这个时刻数据库崩溃了,主库上事务仍然会被正常提交。
MySQL 集群方案
一主多从架构
在 MySQL 的一主多从架构中,类似于 Redis 的主从架构,一个主节点负责处理所有的写操作,而多个从节点负责读取操作,从而提高数据库的读取性能和可用性。一主多从架构有多种复制模式。
异步复制
应用发起更新请求,即进行增加、删除、修改数据的操作时,主实例完成操作后会立即响应应用,同时主实例向备实例异步复制数据。因此,在异步数据复制方式下,备实例不可用时不会影响主实例上的操作,而主实例不可用时可能会导致主备实例数据不一致。
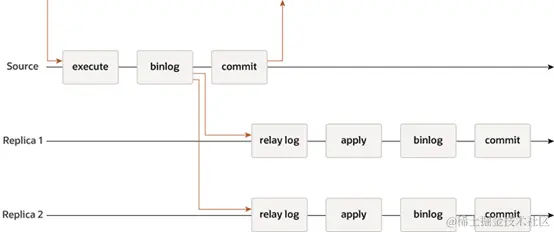
半同步复制
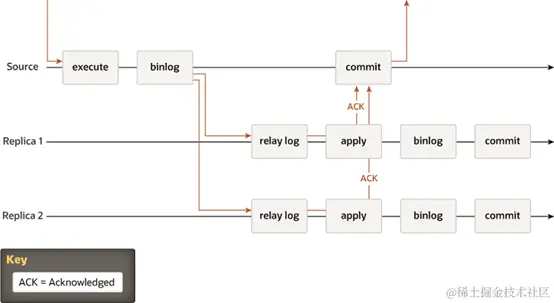
为解决异步同步 Binlog 复制数据会产生主从数据不一致的情况,MySQL 在 5.6 版本中推出半同步复制,在同步数据协议中添加了一个 ACK 同步操作,这样意味主节点在 commit 操作,需要确认最少一个从节点确认接收到并且返回 ACK,只有这样主节点才能正确提交数据。
应用发起的更新在主实例执行完成后,会将日志同步传输到备实例,备实例收到日志,事务就算完成了提交,不需要等待备实例执行日志内容。当备实例不可用或者主备实例间出现网络异常时,半同步会退化为异步。
组复制(MGR)
组复制基于分布式一致性协议(Paxos),事务在主节点提交之前,会将事务的数据发送到各个备节点上(而不是先写入 Binlog),确保超过半数备节点收到事务的数据后,事务才能在主节点提交。
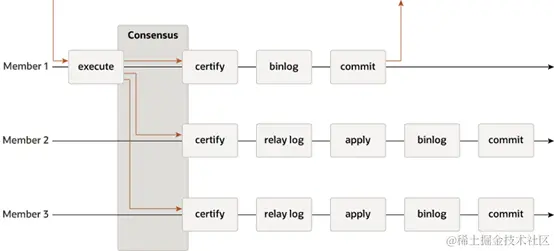
组复制支持单主和多主两种部署模式。
MMM 架构(双主多从)
两主多从架构,还是基于主从复制,增加了 master 备用机制。
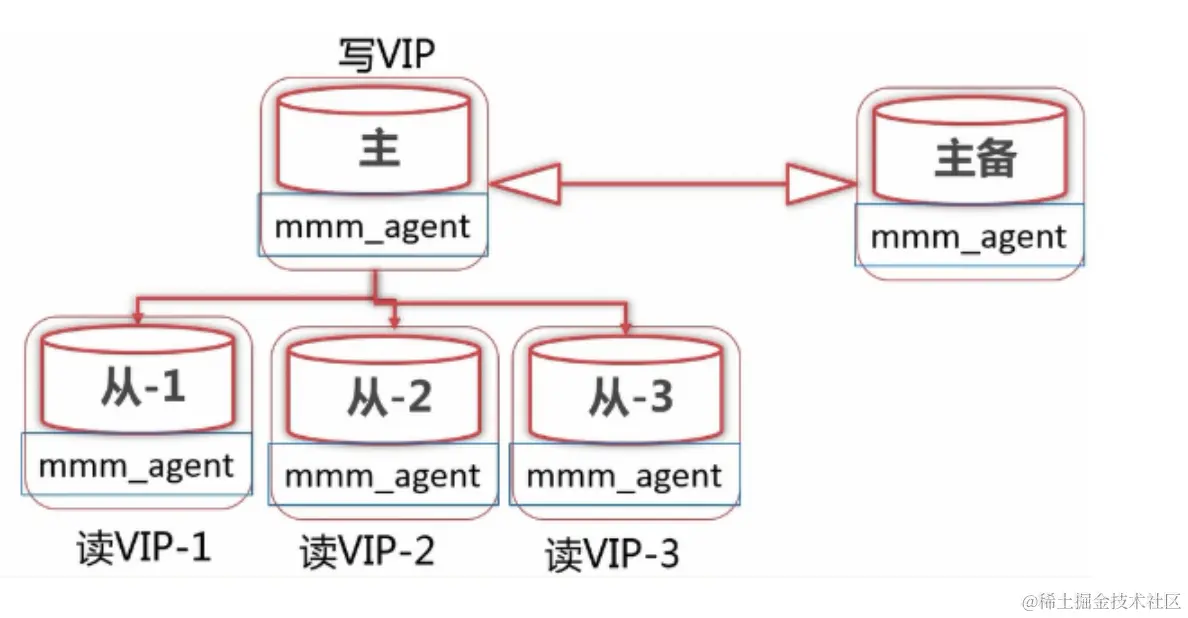
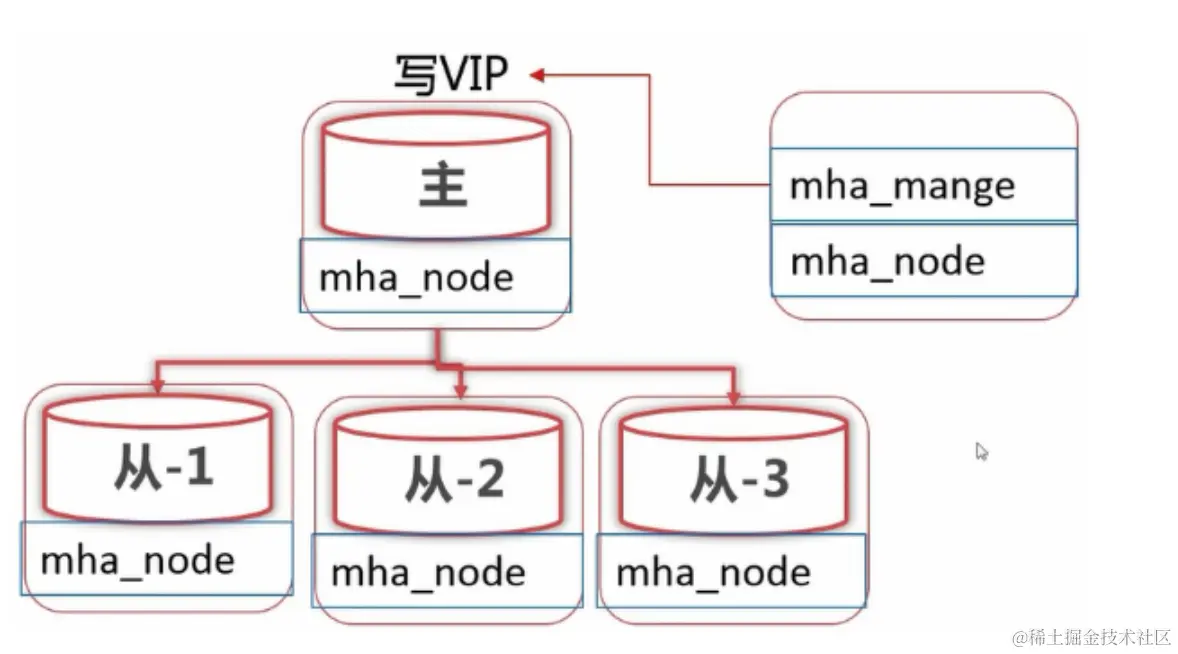
MHA 架构(多主多从)
MHA 基于标准的主从复制提供了故障转换功能。MHA 节点分为管理节点和数据节点。管理节点会定时探测集群中的 master 节点,当 master 节点出现故障时,它可以自动将拥有最新数据的 slave 节点提升为新的 master 节点。
数据库索引
索引的分类
- 聚集索引:又称主键索引,主键索引的叶子节点存的是整行数据,根据主键查询可以直接查询出记录;
- 非聚集索引:又称普通索引,叶子节点内容是索引字段值和对应主键的值,如果需要查询的字段全部命中则无需回表(即覆盖索引),否则需要根据主键进行回表获取目标字段;
- 唯一索引:相比于普通索引增加了唯一性约束,更新操作会先判断是否违反唯一性约束,查找操作取到第一个满足条件的值就会停止;
- 联合索引:相比于普通索引,区别是联合索引由多个字段组成。
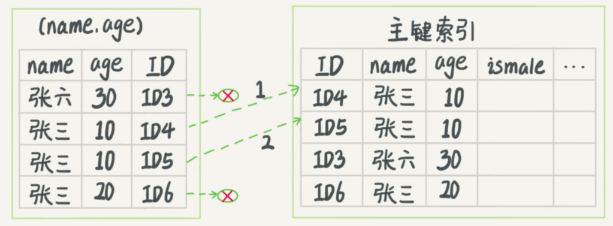
索引下推
以联合索引(name, age)为例。如果现在有一个需求:检索出表中“名字第一个字是张,而且年龄是 10 岁的所有男孩”。那么,SQL 语句是这么写的:
1mysql> select * from tuser where name like '张%' and age=10 and ismale=1;
根据前缀索引规则,所以这个语句在搜索索引树的时候,只能用 “张%",age 索引失效,只能找到符合 “张%” 的列,在 MySQL5.6 之前,会逐个根据主键回表,找到符合 age=10 and ismale=1 的数据。
而 MySQL 5.6 引入的索引下推优化 (index condition pushdown),可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数,如下图所示:
索引结构
B 树
B 树的出现是为了弥合不同的存储级别之间的访问速度上的巨大差异,实现高效的 I/O。
平衡二叉树的查找效率是非常高的,并可以通过降低树的深度来提高查找的效率。但是当数据量非常大,树的存储的元素数量是有限的,这样会导致二叉查找树结构由于树的深度过大而造成磁盘 I/O 读写过于频繁,进而导致查询效率低下。另外数据量过大会导致内存空间不够容纳平衡二叉树所有结点的情况。B 树是解决这个问题的很好的结构。
B 树是一种自平衡树数据结构,B 即 Balance。B 树是二叉搜索树的一般化,因为节点可以有两个以上的子节点。B 树非常适合读取和写入相对较大的数据块(如光盘)的存储系统,通常用于数据库和文件系统。
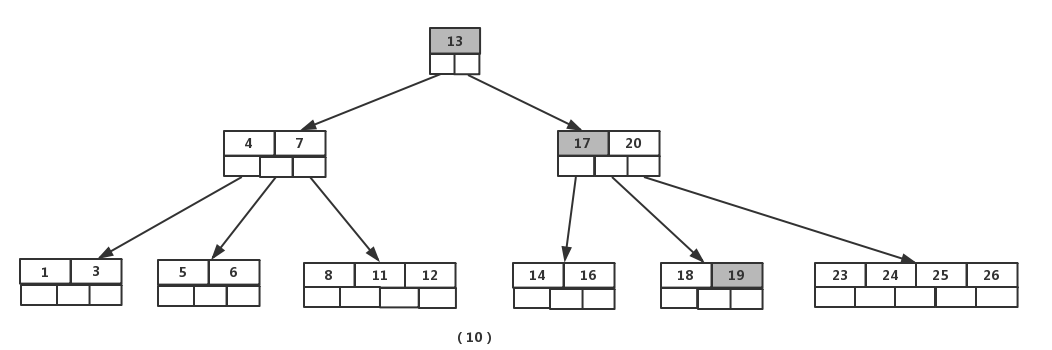
B 树的每个节点的元素可以视为一次 I/O 读取,树的高度表示最多的 I/O 次数,在相同数量的总元素个数下,每个节点的元素个数越多,高度越低,查询所需的 I/O 次数越少。
B+ 树
B+ 树是应文件系统所需而产生的 B 树的变形树。B+ 树相比于 B树的差异及优缺点:
- B+ 树的磁盘读写代价更低,内部节点只存索引,更小,但单点查询不如 B 树
- B+ 树查询效率稳定,树高即是路径长度
- B+ 树便于范围查询,叶子通过双向循环链表连成,在链表上遍历即可
- B+ 树便于插入和删除,冗余节点的存在使得不会出现复杂的树结构变化
MySQL 的不同数据存储引擎所构造的索引 B+ 树有所不同:
对于 InnoDB 引擎,每一个表会存在一棵叶子节点存储所有数据的索引树,这个树一般是主键索引构造的,但如果没有主键,那么会选择一个唯一键作为主键,如果没有唯一键,那么会生成一个 6 位的 row_id 来作为隐式主键。除了这棵树,其他索引字段所构建的索引树,叶子节点只存储主键索引和索引列的值,如果是覆盖索引则无需回表,否则需要通过主键索引再搜一遍主索引树,拿到目标数据。
对于 MyISAM 引擎,任何索引树的叶子节点都是存的数据的地址,需要根据这个地址去数据文件拿到数据,也就是都是二级索引。注意 InnoDB 的数据文件本身就是索引文件,而 MyISAM 索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。
跳表
跳表时间复杂度和 B+ 树差不多,为什么一般采用 B+ 树不采用跳表?
B+ 树是多叉平衡搜索树,扇出高,只需要 3 层左右就能存放 2kw 左右的数据,同样情况下跳表则需要 24 层左右,假设层高对应磁盘 IO,那么 B+ 树的读性能会比跳表要好。
而对于 Redis,它读写全在内存里进行操作,不涉及磁盘 IO,同时跳表实现简单,相比 B+ 树、AVL 树、少了旋转树结构的开销,因此 redis 使用跳表来实现 ZSET,而不是树结构。
索引命中与否
例如有表 t(a,b,c), 建立了联合索引 (a,b),有 sql 语句如下:
1select * from t where b = 2;
这时候是用不了联合索引 (a,b) 的,因为 (a,b) 规定 b 有序的前提是 a 有序,如果 a 不能确定,那 b 在 b+ 树里肯定是无序的,所以无法使用索引 (a,b)。
如果 sql 为:
1select * from t where a = 1 and b = 2 and c = 3;
如何建立索引?
此题正确答法是,建立联合索引 (a,b,c) 或 (c,b,a) 或者 (b,a,c) 都可以,重点要的是将区分度高的字段孜在前面,区分度低的字段放后面。
例如假设区分度由大到小为 b,a,c。那么我们就对 (b,a,c) 建立索引。在执行 sql 的时候,优化器会帮我们调整 where 后 a,b,c 的顺序,让我们用上索引。
分库分表
拆分方法:
- 水平拆分:把一个表的数据给分到多个库的多个表里去,但是每个库的表结构都一样
- 垂直拆分:把一个有很多字段的表给拆分成多个表,或者是多个库上去
迁移为分库分表方法:
- 双写迁移:增删改操作同时作用在新库老库上
- 停机迁移
Reference
- 萨师煊,王珊:《数据库系统概论-第四版》
- B树和B+树详解
- 五分钟搞懂MySQL索引下推
- MySQL 日志:undo log、redo log、binlog 有什么用?
- 分库分表
- 阿里云 - 变更数据复制方式
- 浅析 MySQL 集群部署方案