微服务相关知识整理汇总
Preface
本篇 Blog 对接触到的微服务相关知识做一个整理汇总,仅供查阅学习。如有错误,请批评指正;如发现有文段引用自别处但未在文末加来源,请联系我。
TOC
- Preface
- TOC
- 微服务
- 服务注册与发现
- API 网关
- 分布式配置
- 服务通信
- 负载均衡
- 分布式事务
- 容错机制:服务熔断
- 容错机制:服务降级
- 容错机制:服务限流
- 容错机制:Sentinel
- 分布式一致性协议
- 云原生
- Reference
微服务
基本思想
微服务(Microservices) 是一种软件架构风格,它将一个复杂的应用拆分成一组小型、独立运行的服务。每个微服务都是围绕某个特定的业务功能构建的,并且能够通过轻量级的通信协议(如 HTTP 或消息队列)相互协作。
这种架构以解耦、灵活性和扩展性为核心目标,是对传统单体架构(Monolithic Architecture)的改进。
核心特点
- 单一职责:每个微服务只专注于完成一个业务功能,例如用户管理、订单处理、支付服务等。
- 独立部署:每个微服务可以单独构建、测试、部署和升级,而无需影响其他服务。
- 技术多样性:不同微服务可以使用不同的编程语言、数据库或技术栈,根据具体需求选择最佳实现方式。
- 轻量级通信:微服务通过轻量化的协议(如 HTTP REST API、gRPC 或消息队列)进行通信,避免复杂的交互。
- 自治性:每个微服务独立运行,拥有自己的逻辑、数据存储和业务边界。
- 去中心化管理:微服务架构倾向于分布式治理,各服务独立开发、独立运维。
- 高扩展性:可以根据流量或业务需求,对特定服务进行横向扩展,而不是整体扩展整个系统。
关键组件
为了实现微服务架构,通常需要以下组件的支持:
- 服务注册与发现:实现服务之间动态查找,例如通过 Eureka、Consul 或 Zookeeper。
- API 网关:统一入口,管理微服务之间的请求路由、安全认证和限流等功能,例如 Kong、Spring Cloud Gateway。
- 分布式配置:集中管理配置,支持动态更新,例如 Spring Cloud Config、Consul KV Store。
- 服务通信:HTTP、gRPC、MQ 等。
- 负载均衡:在服务实例之间分发请求,例如使用 Ribbon 或 Spring Cloud LoadBalancer。
- 分布式监控和日志:监控和追踪服务运行状态,例如 Prometheus、Grafana 或分布式追踪工具 Zipkin。
- 容错机制:实现熔断、限流和自动重试功能,例如通过 Hystrix 或 Resilience4j。
设计原因
微服务架构解决了单体架构在开发、扩展和运维中的诸多痛点,特别适合现代复杂应用。它的核心价值在于:
- 灵活性:独立部署与技术栈多样性。每个服务是独立模块,可以单独开发、测试和部署,而无需影响其他服务;不同的微服务可以根据需求选择最合适的技术栈或编程语言。
- 可扩展性:按需扩展,优化资源利用。微服务允许针对不同服务进行独立扩展,而不是整体扩展整个系统;由于服务的独立性,可以在必要时为高负载服务分配更多资源。
- 容错性:故障隔离和快速恢复。一个服务的故障不会直接导致整个系统宕机;微服务部署简单,受影响的服务可以快速替换或恢复。
重要框架
微服务框架 是一种为开发和管理微服务架构提供支持的工具集或技术栈。它们帮助开发者构建、部署和维护微服务,并简化了许多微服务架构中常见的挑战,如上文提到的大多微服务关键组件。
现在主要存在两种微服务框架,SpringCloud 和 Dubbo,它们都是分布式系统中广泛使用的微服务框架。对比如下
| 特性 | Dubbo | Spring Cloud |
|---|---|---|
| 语言支持 | 主要支持 Java(虽然有一些其他语言支持,但偏向 Java) | 支持多语言,尤其是与 REST 和 HTTP 接口交互 |
| 服务治理 | 内置完善的服务治理,如负载均衡、容错、动态路由等,也可以集成 Sentinel | 通过集成其他工具实现服务治理(如 Ribbon、Hystrix、Eureka 等) |
| 服务注册与发现 | 支持多种注册中心(如 Zookeeper、Nacos、Redis) | 提供内置支持,如 Eureka、Consul、Zookeeper |
| 通信协议 | 支持多种协议(Dubbo、HTTP、gRPC 等) | 主要基于 HTTP 和 REST |
| 开发方式 | 通过 Java 接口定义远程调用接口,并通过框架自动实现 | 使用 Spring Boot,通过注解和配置文件配置服务 |
| 扩展性 | 高度可定制,适合高性能服务间通信需求 | 灵活但依赖更多外部组件(如 Hystrix、Ribbon) |
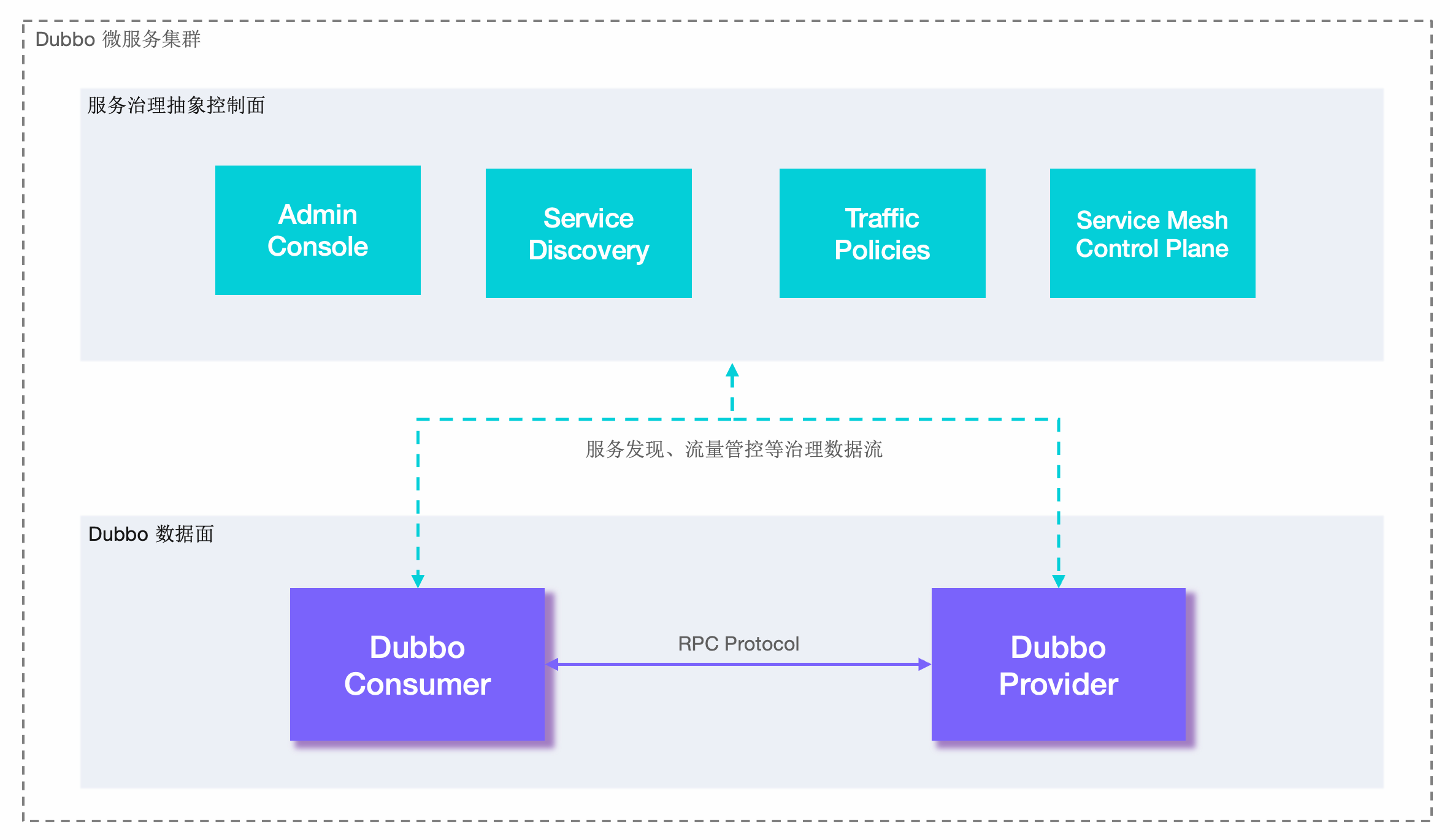
Dubbo 大致框架:
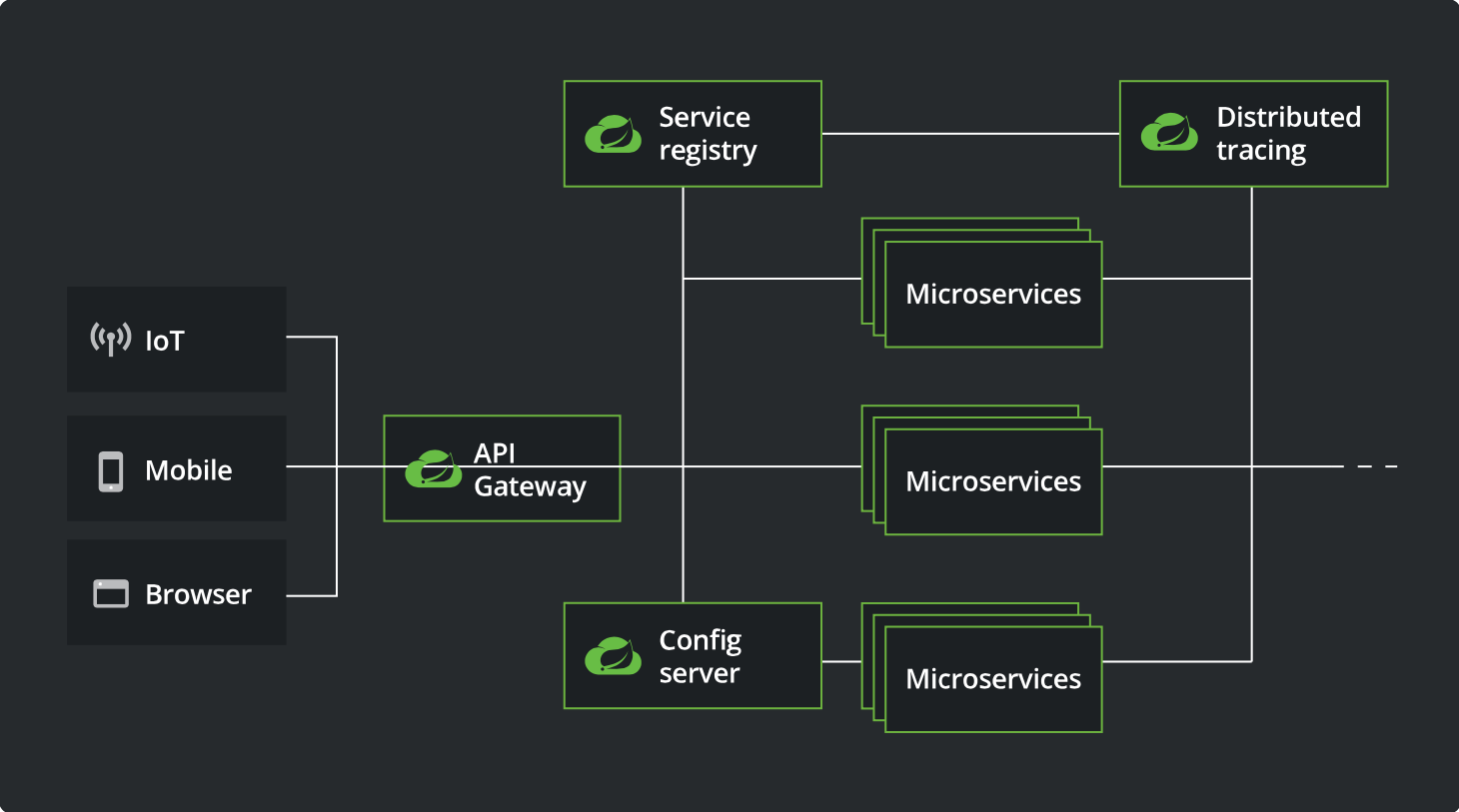
SpringCloud 大致框架:
服务注册与发现
Eureka
Eureka 微服务架构
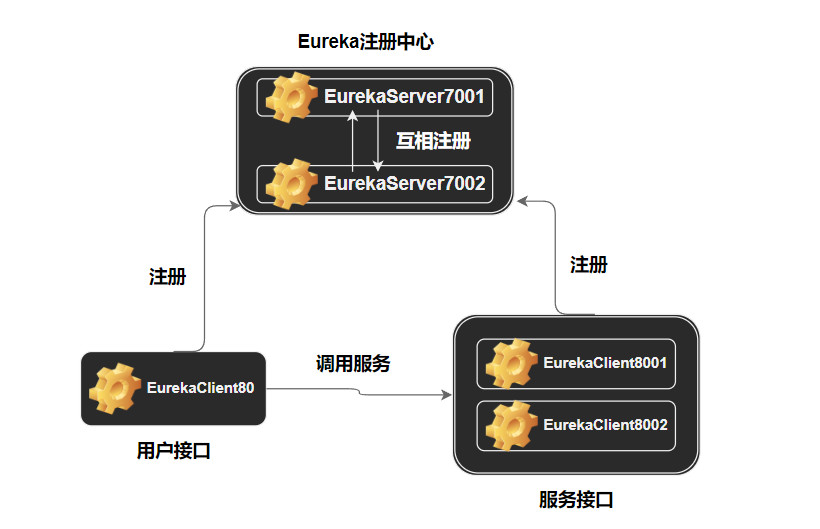
- 服务接口采用集群模式,8001 和 8002 端口都实现支付接口服务。
- 用户接口在运行在 80 端口,调用 8001 和 8002 的服务。
- 注册中心内部也采用集群模式,7001 和 7002 端口都实现注册服务。
Eureka 依赖
1<!-- client端 -->
2<dependency>
3 <groupId>org.springframework.cloud</groupId>
4 <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
5</dependency>
6
7<!-- server端 -->
8<dependency>
9 <groupId>org.springframework.cloud</groupId>
10 <artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
11</dependency>
7001 和 7002 端口关键配置内容
在启动类开启注解 @EnableEurekaServer:
1@SpringBootApplication
2@EnableEurekaServer
3public class EurekaMain7001 {
4 public static void main(String[] args) {
5 SpringApplication.run(EurekaMain7001.class, args);
6 }
7}
接着进行基础配置如下:
对于 7001 端口服务:(7002 端口类似)
1eureka:
2 instance:
3 hostname: eureka7001.com
4 client:
5 # false 表示不向注册中心注册自己
6 register-with-eureka: false
7 # false 表示自己端就是注册中心,我的职责就是维护服务实例,并不需要去检索服务
8 fetch-registry: false
9 service-url:
10 # 设置与Eureka Server交互的地址查询服务和注册服务都需要依赖这个地址
11 defaultZone: http://eureka7002.com:7002/eureka/
注意 defaultZone 配置指向其他注册服务端口,需满足“相互注册”。
另外,eureka7001.com 和 eureka7002.com 其实配置指向 localhost,这里只是为了模拟多台机器。
8001 和 8002 端口关键配置内容
注:(2023-03-20 更新)
Eureka version 4.0.0 onwards, which is being used in Spring Cloud 2022.0.0, you do not need to explicitly register using the annotation @EnableEurekaClient, It automatically gets registered as client if spring-cloud-starter-netflix-eureka-client is on the class path.
By having spring-cloud-starter-netflix-eureka-client on the classpath, your application automatically registers with the Eureka Server. Configuration is required to locate the Eureka server.
否则需要开启 @EnableEurekaClient 注解:
1@SpringBootApplication
2@EnableEurekaClient
3public class PaymentMain8001 {
4 public static void main(String[] args) {
5 SpringApplication.run(PaymentMain8001.class, args);
6 }
7}
接着进行基础配置如下:
1# eureka 配置部分
2eureka:
3 client:
4 register-with-eureka: true # 配置是否进行注册
5 fetch-registry: true # 配置是否从eureka注册中心拉取注册信息
6 service-url: # 配置注册地址
7 defaultZone: http://eureka7001.com:7001/eureka, http://eureka7002.com:7002/eureka
8 instance:
9 instance-id: payment8001
10 prefer-ip-address: true # 鼠标到instance上会显示ip
11
12# 配置服务名称
13spring:
14 application:
15 name: cloud-payment-service
这个服务名很重要,用于配置后面用户接口的服务地址。
80 端口关键配置内容
开启 @EnableEurekaClient 注解:
1@SpringBootApplication
2@EnableEurekaClient
3public class OrderMain80 {
4 public static void main(String[] args) {
5 SpringApplication.run(OrderMain80.class, args);
6 }
7}
配置 RestTemplate,开启负载均衡:
1@Configuration
2public class ApplicationContextConfig {
3 @Bean
4 @LoadBalanced // 赋予负载均衡能力
5 public RestTemplate getRestTemplate() {
6 return new RestTemplate();
7 }
8}
Controller 指定负载均衡访问服务地址:
1@RestController
2@Slf4j
3public class OrderController {
4 public static final String PAYMENT_URL = "http://CLOUD-PAYMENT-SERVICE";
5
6 @Resource
7 private RestTemplate restTemplate;
8
9 @GetMapping("/consumer/payment/create")
10 public CommonResult<Integer> create(@RequestParam(value = "serial") String serial) {
11 Payment payment = new Payment(0L, serial);
12 log.info("serial: " + serial);
13 return restTemplate.postForObject(PAYMENT_URL + "/payment/create", payment, CommonResult.class);
14 }
15
16 @GetMapping("/consumer/payment/get/{id}")
17 public CommonResult<Payment> getPayment(@PathVariable("id") Long id) {
18 return restTemplate.getForObject(PAYMENT_URL + "/payment/get/" + id, CommonResult.class);
19 }
20}
注意:
- Controller 必须是 GetMapping,然后通过
restTemplate.getForObject()或restTemplate.postForObject()发送 get 或 post 请求。 - 配置的服务地址前缀为
http://加上服务接口对应的 application-name 的全大写形式。
效果展示
访问 http://localhost:7001 或者 http://eureka7001.com:7001
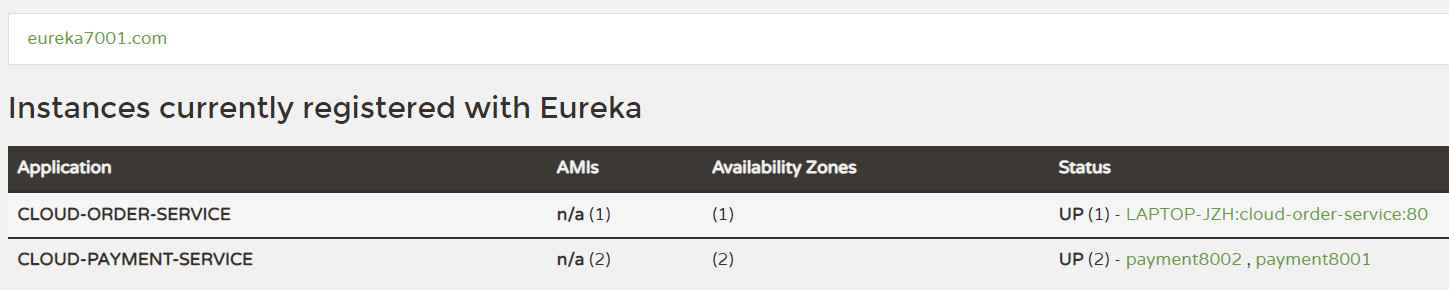
可见所有服务已经成功注册。
访问 http://localhost/consumer/payment/get/3
成功返回结果,服务端口动态变换:
1{
2 "code":200,
3 "message":"查询成功,访问端口:8001",
4 "data":{"id":3,"serial":"ajefskldfa"}
5}
1{
2 "code":200,
3 "message":"查询成功,访问端口:8002",
4 "data":{"id":3,"serial":"ajefskldfa"}
5}
Nacos
Nacos 是阿里巴巴开源的一款动态服务发现、配置管理和服务管理平台,主要用于微服务架构中。Nacos 的名字来源于 Dynamic Naming and Configuration Service,它致力于帮助开发者实现服务的高可用性和动态管理。
主要功能
- 服务注册与发现:微服务实例启动时会将自己的地址和元数据注册到 Nacos,注册后,Nacos 会维护服务实例的健康状态;其他服务可以通过 Nacos 查询可用的服务实例列表,支持 DNS 和 HTTP REST 两种服务发现机制。
- 配置管理:应用的所有配置可以集中存储在 Nacos 中,简化配置管理,配置可以动态刷新,服务无需重启即可更新配置,支持多环境和多租户。
- 动态服务配置:Nacos 可以根据流量动态调整服务的路由策略,结合服务网格实现流量分配与治理。
基本架构
核心组件:
- 服务端:提供服务注册、发现、配置管理和健康检查等功能。
- 客户端:微服务通过 Nacos SDK 与服务端交互,实现注册、发现和配置读取。
工作流程:
- 服务实例启动时,向 Nacos 注册自己的元数据。
- 其他服务通过 Nacos 获取服务列表,并根据路由策略调用目标服务。
- 配置更新后,Nacos 将变更通知到相关的服务实例。
实践测试
总体架构
在一台 CentOS 主机上部署,版本为 7.9,IP 为 192.168.1.127。
通过 docker 创建三台 nacos 环境的机器,端口均运行在 8848,分别映射到主机的 8848,8858,8868 端口上,名称(hostname)分别为 nacos-server1,nacos-server2,nacos-server3。
主机通过 nginx 监听 8080 端口,通过负载均衡将请求转发到三台 nacos 机器上。
主机作为数据库源,使用 mysql 作为数据库,端口为 3306,三台机器都安装 mysql 环境,端口运行在 3306,映射到主机 3307 端口。
服务说明
创建一个简单的服务,注册到上述 nacos 环境中,通过在 bootstrap.yaml 中读取 nacos 配置来验证环境是否配置成功。
搭建 nacos 环境
在 nacos 官网下载 nacos-docker 到主机上,编辑 docker-compose.yaml 文件。
根据官网说明,在 nacos2 中需要额外暴露两个端口,分别偏移 8848 这个端口 1000 和 1001。
1version: "3"
2services:
3 nacos1:
4 hostname: nacos-server-1
5 container_name: nacos1
6 image: nacos/nacos-server:${NACOS_VERSION}
7 volumes:
8 - ./cluster-logs/nacos1:/home/nacos/logs
9 - ./init.d/custom.properties:/home/nacos/init.d/custom.properties
10 ports:
11 - "8848:8848"
12 - "9848:9848" # 偏移 1000
13 - "9849:9849" # 偏移 1001
14 - "9555:9555"
15 env_file:
16 - ../env/nacos-hostname.env
17 restart: always
18 depends_on:
19 - mysql
20
21 nacos2:
22 hostname: nacos-server-2
23 image: nacos/nacos-server:${NACOS_VERSION}
24 container_name: nacos2
25 volumes:
26 - ./cluster-logs/nacos2:/home/nacos/logs
27 - ./init.d/custom.properties:/home/nacos/init.d/custom.properties
28 ports:
29 - "8858:8848"
30 - "9858:9848"
31 - "9859:9849"
32 env_file:
33 - ../env/nacos-hostname.env
34 restart: always
35 depends_on:
36 - mysql
37
38 nacos3:
39 hostname: nacos-server-3
40 image: nacos/nacos-server:${NACOS_VERSION}
41 container_name: nacos3
42 volumes:
43 - ./cluster-logs/nacos3:/home/nacos/logs
44 - ./init.d/custom.properties:/home/nacos/init.d/custom.properties
45 ports:
46 - "8868:8848"
47 - "9868:9848"
48 - "9869:9849"
49 env_file:
50 - ../env/nacos-hostname.env
51 restart: always
52 depends_on:
53 - mysql
54
55 mysql:
56 container_name: mysql
57 image: nacos/nacos-mysql:5.7
58 env_file:
59 - ../env/mysql.env
60 volumes:
61 - ./mysql:/var/lib/mysql
62 ports:
63 - "3307:3306"
配置数据库信息
通过官网提供的 sql 脚本在主机建好数据库。
接着指定 mysql 数据库源信息,编辑 env/nacos-hostname.env 文件如下:
1PREFER_HOST_MODE=hostname # hostname 模式
2NACOS_SERVERS=nacos-server-1 nacos-server-2 nacos-server-3
3MYSQL_SERVICE_HOST=192.168.1.127
4MYSQL_SERVICE_DB_NAME=nacos_config
5MYSQL_SERVICE_PORT=3306
6MYSQL_SERVICE_USER=****
7MYSQL_SERVICE_PASSWORD=******
注意填写好主机的 mysql 账号密码。
最后指定 docker 中 mysql 信息,编辑 env/mysql.env 文件即可:
1MYSQL_ROOT_PASSWORD=******
2MYSQL_DATABASE=nacos_config
3MYSQL_USER=****
4MYSQL_PASSWORD=******
运行 docker
1docker-compose up
2
3nacos2 | 2022-08-07 07:05:41,147 INFO Nacos started successfully in cluster mode. use external storage
4nacos2 |
5nacos1 | 2022-08-07 07:05:41,194 INFO Nacos is starting...
6nacos1 |
7nacos1 | 2022-08-07 07:05:41,240 INFO Nacos started successfully in cluster mode. use external storage
8nacos1 |
9nacos3 | 2022-08-07 07:05:42,097 INFO Nacos is starting...
10nacos3 |
11nacos3 | 2022-08-07 07:05:42,135 INFO Nacos started successfully in cluster mode. use external storage
搭建 nginx 环境
首先安装 nginx,接着编辑 /etc/nginx/nginx.conf 文件如下:
1...
2
3http {
4 ...
5 upstream nacos-servers {
6 server 192.168.1.127:8848;
7 server 192.168.1.127:8858;
8 server 192.168.1.127:8868;
9 }
10 server {
11 location / {
12 proxy_pass http://nacos-servers;
13 }
14 listen 8080;
15 }
16}
监听 8080 端口,通过 upstream 转发到三台机器上。
接着运行 nginx 即可:
1nginx -c /etc/nginx/nginx.conf
创建微服务
依赖导入:
1<dependency>
2 <groupId>com.alibaba.cloud</groupId>
3 <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
4</dependency>
5<dependency>
6 <groupId>com.alibaba.cloud</groupId>
7 <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
8</dependency>
基本配置。编辑 bootstarp.yaml 如下:(nacos 的地址即 nginx 配置好的地址 192.168.1.127:8080)
1spring:
2 cloud:
3 nacos:
4 discovery:
5 server-addr: 192.168.1.127:8080
6 config:
7 server-addr: 192.168.1.127:8080
8 file-extension: yaml
9 profiles:
10 active: prod
11 application:
12 name: nacos-config-client
13server:
14 port: 9669
编写服务
启动类开启 @EnableDiscoveryClient 注解,然后编写接口:
1@RefreshScope
2@RestController
3@Slf4j
4public class ConfigController {
5 @Value("${config.version}")
6 private String version;
7
8 @GetMapping("/v")
9 public String getVersion() {
10 return version;
11 }
12}
完成测试
- 访问 192.168.1.127:8080,成功访问并登录;
- 查看集群管理的节点列表,三个前缀名为 nacos-server 的节点都处在 UP 状态;
- 编写
nacos-config-client-prod.yaml文件,为微服务名+环境的格式,新增变量config.version为 1.0; - 开启微服务,再查看服务列表,名为 nacos-config-client 的服务已经成功注册,访问接口 /v,返回 1.0;
- 修改配置,version 改为 2.0,再次访问 /v 接口,返回 2.0。
API 网关
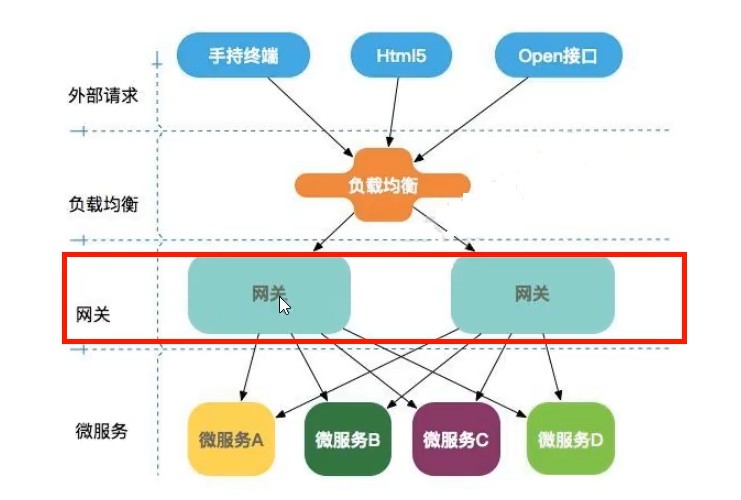
网关的作用
如图所示,网关介于外部请求和具体微服务之间,在不暴露内部微服务端口的情况下,通过一个或者多个指定的网关端口统一地处理外部各种请求。
SpringCloud Gateway 实践
依赖引入
除了基本依赖以外,引入下列依赖:
1<dependency>
2 <groupId>org.springframework.cloud</groupId>
3 <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
4</dependency>
5<dependency>
6 <groupId>org.springframework.cloud</groupId>
7 <artifactId>spring-cloud-starter-gateway</artifactId>
8</dependency>
注意不能引入 web 相关依赖,因为 Gateway 是基于 WebFlux 的。
文件配置
列出部分重要配置:
1server:
2port: 9669
3cloud:
4 gateway:
5 discovery:
6 locator:
7 enabled: true # 开启从注册中心动态创建路由的功能,利用微服务名进行路由
8 routes:
9 - id: path_route
10 uri: lb://CLOUD-PAYMENT-SERVICE # lb:负载均衡
11 predicates:
12 - Path=/payment/**
13 - After=2022-07-26T17:33:52.449+08:00[Asia/Shanghai] # ZonedDateTime.now()
14 - Cookie=username,jzh
注意点如下:
- 9669 端口作为网关端口;
- uri 中 http 改为了 lb,用于负载均衡;
- predicates,即断言,上述断言为:
- 匹配路径:/payment/**;
- 开始允许访问时间:
ZonedDateTime.now()(Java函数获取该格式时间) - 携带cookie:
key=username, value=jzh
过滤器配置
实现 GlobalFilter,Ordered,重写方法即可:
1@Component
2@Slf4j
3public class MyGlobalFilter implements GlobalFilter, Ordered {
4 @Override
5 public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
6 String username = exchange.getRequest().getQueryParams().getFirst("username");
7 if (username == null) {
8 log.info("username lost");
9 exchange.getResponse().setStatusCode(HttpStatus.NOT_ACCEPTABLE);
10 return exchange.getResponse().setComplete();
11 }
12 return chain.filter(exchange);
13 }
14
15 @Override
16 public int getOrder() {
17 return 0;
18 }
19}
定义了 url 中携带必须携带一个 key 为 username 的参数。
测试
注意先开启指定的微服务,访问http://localhost:9669/payment/get/11?username=aaa(同时配好cookie),成功返回结果:
1{
2 "code": 200,
3 "data": {
4 "serial": "8asd8sa2j",
5 "id": 11
6 },
7 "message": "查询成功,访问端口:8001"
8}
再刷新,发现端口动态变化为8002,负载均衡功能也测试成功。
分布式配置
基本概念
分布式配置 是一种在分布式系统或微服务架构中,用于集中管理和分发应用配置的机制。它解决了多服务、多节点环境下配置管理的复杂性,确保各服务实例能够动态获取和更新所需的配置数据。
常用分布式配置工具有 Spring Cloud Config、Consul、以及之前提到的 Nacos。
Spring Cloud Config
这里结合 Bus 来实现分布式配置。当全局配置修改时,需要通知各个微服务,一个一个地通知是非常耗时的,如果可以通过广播的方式快速将消息传递出去就轻松多了,而通过 Bus 即可实现这一点。
操作方法
- 在 6996 端口通过 git 拉取全局配置,相当于一个 ConfigServer;
- 6886 和 6776 端口作为 ConfigClient;
- Bus 结合 RabbitMQ 实现,修改配置时,只通知 ConfigServer,达到消息广播的效果。
依赖引入
1<!-- ConfigServer 端 -->
2<dependency>
3 <groupId>org.springframework.cloud</groupId>
4 <artifactId>spring-cloud-starter-bus-amqp</artifactId>
5</dependency>
6<dependency>
7 <groupId>org.springframework.cloud</groupId>
8 <artifactId>spring-cloud-config-server</artifactId>
9</dependency>
10
11<!-- ConfigClient 端 -->
12<dependency>
13 <groupId>org.springframework.cloud</groupId>
14 <artifactId>spring-cloud-starter-bus-amqp</artifactId>
15</dependency>
16<dependency>
17 <groupId>org.springframework.cloud</groupId>
18 <artifactId>spring-cloud-starter-config</artifactId>
19</dependency>
基础配置
1# ConfigServer 端
2# application.yaml
3spring:
4 cloud:
5 config:
6 server:
7 git:
8 # github 项目地址
9 uri: https://github.com/akynazh/SpringCloud-Demo.git
10 # 指定搜索项目下 config 文件夹中的内容
11 search-paths:
12 - config
13 # 指定分支
14 default-label: master
15 rabbitmq:
16 host: localhost
17 port: 5672
18 username: guest
19 password: guest
20management:
21 endpoints:
22 web:
23 exposure:
24 # 通过 /actuator/bus-refresh 可进行事件通知
25 include: "bus-refresh"
以后,运维人员修改 config 时,即可通过 http://localhost:6996/actuator/bus-refresh 发送 POST 请求进行消息通知。
1# ConfigClient 端
2# bootstrap.yml | 可以加载全局配置
3spring:
4 application:
5 name: cloud-config-client
6 cloud:
7 config:
8 label: master # 分支
9 name: config # 文件名
10 profile: dev # 环境
11 uri: http://localhost:6996 # 全局配置加载地址
12 rabbitmq:
13 host: localhost
14 port: 5672
15 username: guest
16 password: guest
值得注意的地方:
第一,config 文件名编写需要遵循一定规则,我选择的是 {name}-{profile}.yml 的格式,然后如上配置文件应该填写对应内容。
第二,application-name 可以用于后续选择性通知,如只想通知 6776,可通过 POST 请求访问如下地址:http://localhost:6996/actuator/bus-refresh/cloud-config-client:6776。
编写相关接口
在 ConfigServer 添加 @EnableConfigServer 注解,在 ConfigClient 端编写接口:
1@RestController
2@Slf4j
3public class MyController {
4
5 @Resource
6 private Environment env;
7
8 @Value("${server.port}")
9 String port;
10
11 @GetMapping("/v")
12 public String getVersion() {
13 return "port: " + port + "\t " + env.getProperty("config.version");
14 }
15}
测试
启动 RabbitMQ:
1.sbin\rabbitmq-service.bat start
默认启动在 5672 端口。(图形界面在 15672 端口)
加载配置测试。访问:http://localhost:6996/master/config-dev.yml,会从 github 加载得到:
1config:
2 label: master
3 profile: dev
4 version: 3.0
访问:http://localhost:6776/v,得到:
1port: 6776 3.0
6886 得到相同结果,证明成功加载全局配置。
修改配置测试。修改配置 version 为 3.6,提交,发送请求如下:
1curl -X POST "http://localhost:6996/actuator/bus-refresh"
发现三个端口 version 均改为 3.6,测试通过。
修改配置 version 为 3.9,提交,发送请求如下:
1curl -X POST "http://localhost:6996/actuator/bus-refresh/cloud-config-client:6776"
发现 6996 和 6776 的 version 为 3.9,而 6886 的 version 仍为 3.6,测试通过。
服务通信
采用协议
- HTTP
- RPC
- gRPC
- Dubbo
gRPC 协议介绍
gRPC 是 Google 基于 HTTP/2 以及 protobuf 的开发的协议:
- gRPC 是高性能的,由于是基于 HTTP/2,支持多路复用、头部压缩、低延迟和二进制传输,大幅提高了数据传输效率。
- Protobuf 采用高效的二进制序列化,比 JSON 或 XML 更快且数据更小,Protobuf 一方面选用了 VarInts 对数字进行编码,解决了效率问题;另一方面给每个字段指定一个整数编号,传输的时候只传字段编号,解决了冗余问题。
- 使用 Protobuf 定义服务接口,提供强类型约束,减少通信中的解析错误并简化代码生成。
- gRPC 支持全双工通信,支持客户端流式、服务端流式和双向流式通信,适用于需要实时或高频数据传输的场景。
Dubbo 协议介绍
Dubbo 缺省协议采用单一长连接和 NIO 异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况。dubbo RPC 是 dubbo 体系中最核心的一种高性能、高吞吐量的远程调用方式。
负载均衡
基本思想
负载均衡(LB),即是对于用户的某个请求,将有多个相同功能的服务点服务该请求,某个服务点挂了,其他服务点还是可以进行服务,这样就实现了系统的高可用。
关于集中式 LB 和进程内 LB
- 集中式 LB
在服务的消费方和提供方之间使用独立的 LB 设施,(软硬件均可,软件如 Nginx,硬件如 F5),由该设施负责把访问请求通过某种策略(可自行指定)转发至服务的提供方。
- 进程内 LB
将 LB 逻辑集成到消费方,消费方从服务注册中心获知有哪些地址可用,然后自己再从这些地址中选择出一个合适的服务点进行服务。
Ribbon 属于进程内 LB,它只是一个类库,集成于消费方进程,消费方通过它获取服务提供方的地址。
Dubbo
Dubbo 内置了 client-based 负载均衡机制,如下是当前支持的负载均衡算法,结合上文提到的自动服务发现机制,消费端会自动使用 Weighted Random LoadBalance 加权随机负载均衡策略 选址调用。
如果要调整负载均衡算法,以下是 Dubbo 框架内置的负载均衡策略:
- 加权随机:默认算法,默认权重相同
- 加权轮询:借鉴于 Nginx 的平滑加权轮询算法,默认权重相同
- 最少活跃优先 + 加权随机:背后是能者多劳的思想
- 最短响应优先 + 加权随机:更加关注响应速度
- 一致性哈希:确定的入参,确定的提供者,适用于有状态请求
- Power of Two Choice:随机选择两个节点后,继续选择“连接数”较小的那个节点
- 自适应负载均衡:在 P2C 算法基础上,选择二者中 load 最小的那个节点
Dubbo 框架的默认策略是 random 加权随机负载均衡。如果要调整策略,只需要设置 loadbalance 相应取值即可。为所有服务调用指定全局配置:
1dubbo:
2 consumer:
3 loadbalance: roundrobin
Ribbon
Ribbon 是一个用于微服务架构的 客户端负载均衡工具。它的核心功能是通过客户端侧的负载均衡,帮助微服务在调用其他服务时动态选择最优的实例。
具体功能
-
客户端负载均衡:
- Ribbon 会维护目标服务实例列表,并根据配置的负载均衡策略(如轮询、随机等)在这些实例间分发请求。
- 例如,当一个服务需要访问其他服务的多个实例时,Ribbon 会动态决定使用哪一个实例。
-
服务发现集成:
- Ribbon 可以与服务注册中心(如 Eureka)集成,动态获取服务实例列表,无需手动更新配置。
-
自定义负载均衡策略:
- 提供多种内置策略(如轮询、随机、加权轮询等)。
- 允许开发者实现自定义策略以满足特定业务需求。
-
故障检测与重试:
- Ribbon 支持健康检查,可在目标服务实例不可用时自动排除。
- 提供自动重试功能,增加请求成功的可能性。
基本架构
Ribbon 是一个完全在客户端运行的负载均衡器。其基本工作流程如下:
- 客户端通过 Ribbon 请求目标服务。
- Ribbon 查询服务实例列表(可能来自配置文件,也可能通过 Eureka 动态获取)。
- 根据负载均衡策略选择一个实例。
- 将请求发送到选定的实例。
实践测试
Ribbon 通常与 Spring Cloud 一起使用,在微服务环境中,服务消费者通过 Ribbon 调用服务提供者。
如果与 Eureka 集成,则导入依赖如下:
1<dependency>
2 <groupId>org.springframework.cloud</groupId>
3 <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> <!-- 已经包含了ribbon -->
4</dependency>
然后开启注解:
1@Configuration
2public class ApplicationContextConfig {
3 @Bean
4 @LoadBalanced // 赋予负载均衡能力
5 public RestTemplate getRestTemplate() {
6 return new RestTemplate();
7 }
8}
访问相同服务名地址即可。下面来指定 Ribbon 负载均衡规则,所有规则均实现了 IRule 接口,通过查看接口实现类即可知道规则的种类。
默认是 RoundRobinRule(轮询)这一规则。下面修改为 RandomRule(随机)这一规则,在启动类扫描不到的包下创建规则:
1@Configuration
2public class MyRibbonRule {
3 @Bean
4 public IRule myRule() {
5 return new RandomRule();
6 }
7}
最后在启动类指定规则:
1@SpringBootApplication
2@EnableEurekaClient
3@RibbonClient(name="CLOUD-PAYMENT-SERVICE", configuration = MyRibbonRule.class)
4public class OrderMain80 {
5 public static void main(String[] args) {
6 SpringApplication.run(OrderMain80.class, args);
7 }
8}
自己实现负载均衡
编写 LB 接口即实现类
要实现负载均衡,首先应获取得到所有的服务实例 ServiceInstance。
1public interface LoadBalancer {
2 ServiceInstance getServiceInstance(List<ServiceInstance> instances);
3}
通过自旋锁获取新值,取余 ServiceInstance 个数,得到目标 ServiceInstance 下标。
1@Component
2public class MyLoadBalancer implements LoadBalancer {
3 private AtomicInteger aint = new AtomicInteger(0);
4 public final int myCAS() {
5 int expect, next;
6 for (;;) {
7 expect = aint.get();
8 next = (expect + 1) % Integer.MAX_VALUE;
9 if (aint.compareAndSet(expect, next)) return next;
10 }
11 }
12 @Override
13 public ServiceInstance getServiceInstance(List<ServiceInstance> instances) {
14 if (instances == null || instances.size() <= 0) return null;
15 return instances.get(myCAS() % instances.size());
16 }
17}
编写 Controller
注意需要通过获取得到的 ServiceInstance 的 uri 作为访问前缀。
1@Resource
2private RestTemplate restTemplate;
3
4@Resource
5private EurekaDiscoveryClient discoveryClient;
6
7@Resource
8private LoadBalancer loadBalancer;
9
10@GetMapping("/consumer/payment/lb")
11public String lbTest() {
12 List<ServiceInstance> instances = discoveryClient.getInstances("CLOUD-PAYMENT-SERVICE");
13 ServiceInstance instance = loadBalancer.getServiceInstance(instances);
14 log.info("lbtest: " + instance.getUri().toString());
15
16 return restTemplate.getForObject(instance.getUri() + "/payment/lb", String.class);
17}
接着访问 /consumer/payment/lb 接口即可完成负载均衡的测试。
分布式事务
基本思想
分布式系统会把一个应用系统拆分为可独立部署的多个服务,各个服务的事务会操作各自的数据库,因此需要服务与服务之间远程协作才能完成事务操作。这种分布式系统环境下由不同的服务之间通过网络远程协作完成事务称之为分布式事务。
例如用户下一个订单,需要首先创建订单,然后删减库存,接着扣除用户的金钱,最后完成订单。这个过程中,每个操作都可以作为一个微服务,每个微服务操作对应的数据库,而各个数据库可能分布在不同机器上,那么分布式事务就产生了,我们要确保一个事务被正确地处理,必须解决好分布式事务的数据提交与回滚。
Seata
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。
Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
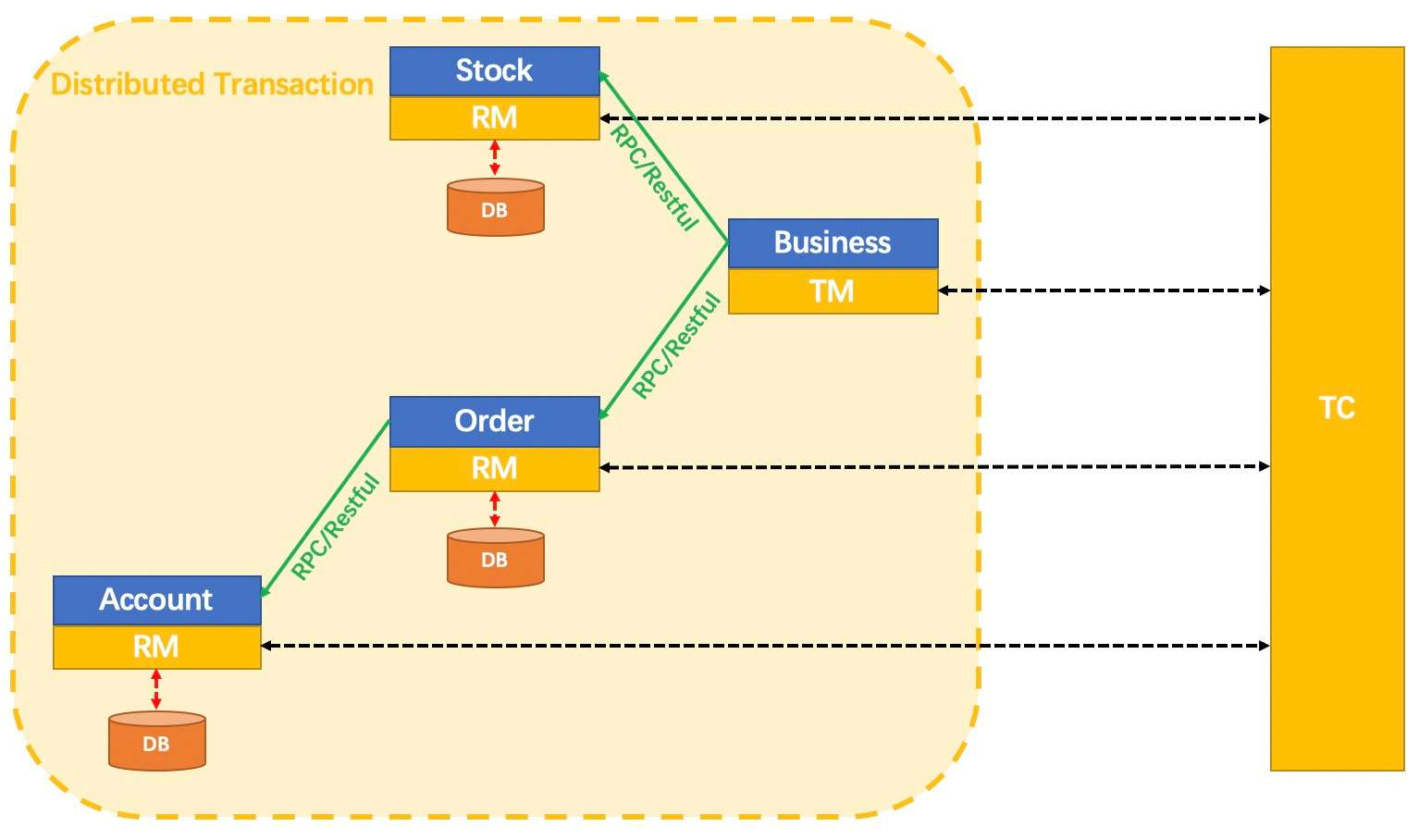
- TC (Transaction Coordinator):事务协调者,维护全局和分支事务的状态,驱动全局事务提交或回滚。
- TM (Transaction Manager):事务管理器,定义全局事务的范围:开始全局事务、提交或回滚全局事务。
- RM (Resource Manager):资源管理器,管理分支事务处理的资源,与 TC 交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
在 Seata 中,分布式事务的执行流程:
- TM 开启分布式事务(TM 向 TC 注册全局事务记录);
- 按业务场景,编排数据库、服务等事务内资源(RM 向 TC 汇报资源准备状态 );
- TM 结束分布式事务,事务一阶段结束(TM 通知 TC 提交/回滚分布式事务);
- TC 汇总事务信息,决定分布式事务是提交还是回滚;
- TC 通知所有 RM 提交/回滚 资源,事务二阶段结束;
编码测试
架构说明。开启三个微服务,创建订单服务,删减库存服务,扣除用户金钱服务,均注册到 nacos。
由订单服务作为入口,首先创建订单,然后删减库存,最后扣钱,完成订单,各个服务数据存取操作均处于不同数据库中。使用 seata 作为分布式事务解决方案,也注册到 nacos 中。
初始化 Seata
下载安装 Seata 1.0.0,然后在 MySQL 新建 seata 表:sql 链接。
配置 Seata
配置 type 类型为 nacos:
1# registry.conf
2registry {
3 # file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
4 type = "nacos"
5
6 nacos {
7 serverAddr = "localhost:8848"
8 namespace = ""
9 cluster = "default"
10 }
11...
12}
my_test_tx_group 修改为自定义 group 名,store.mode 改为 db,修改 db 配置内容:
1# file.conf
2service {
3 #transaction service group mapping
4 vgroup_mapping.jzh = "default"
5 #only support when registry.type=file, please don't set multiple addresses
6 default.grouplist = "127.0.0.1:8091"
7 #disable seata
8 disableGlobalTransaction = false
9}
10
11## transaction log store, only used in seata-server
12store {
13 ## store mode: file、db
14 mode = "db"
15
16 ## file store property
17 file {
18 ## store location dir
19 dir = "sessionStore"
20 }
21
22 ## database store property
23 db {
24 ## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp) etc.
25 datasource = "dbcp"
26 ## mysql/oracle/h2/oceanbase etc.
27 db-type = "mysql"
28 driver-class-name = "com.mysql.jdbc.Driver"
29 url = "jdbc:mysql://127.0.0.1:3306/seata"
30 user = "root"
31 password = "******"
32 }
33}
启动 Seata
1bin\seata-server.bat -p 8091 -h 127.0.0.1 -m db
编写微服务模块
创建 seata_order,seata_account,seata_storage 三个数据库,创建对应数据表,以及 undo_log 表:数据库脚本地址。
将 file.conf 和 registry.conf 复制到微服务对应配置文件目录下。
在 application.yaml 指明自定义的服务组:
1spring:
2 cloud:
3 alibaba:
4 seata:
5 tx-service-group: jzh
导入 seata 依赖(指定好自己用的 seata 版本):
1<dependency>
2 <groupId>com.alibaba.cloud</groupId>
3 <artifactId>spring-cloud-starter-alibaba-seata</artifactId>
4 <exclusions>
5 <exclusion>
6 <artifactId>seata-all</artifactId>
7 <groupId>io.seata</groupId>
8 </exclusion>
9 </exclusions>
10</dependency>
11<dependency>
12 <groupId>io.seata</groupId>
13 <artifactId>seata-all</artifactId>
14 <version>1.0.0</version>
15</dependency>
多数据源配置
seata 需要处理多个数据源,因此必须配置多数据源,然而 DataSourceAutoConfiguration.class 默认会帮我们自动配置单数据源,所以必须排除它。
启动类添加如下注解即可:
1@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
同时指定多数据源配置如下:
1@Configuration
2public class DataSourceProxyConfig {
3 @Bean
4 @ConfigurationProperties(prefix = "spring.datasource")
5 public DataSource druidDataSource() {
6 return new DruidDataSource();
7 }
8
9 @Bean
10 public DataSourceProxy dataSourceProxy(DataSource dataSource) {
11 return new DataSourceProxy(dataSource);
12 }
13
14 @Bean
15 public SqlSessionFactory sqlSessionFactoryBean(DataSourceProxy dataSourceProxy) throws Exception {
16 SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
17 sqlSessionFactoryBean.setDataSource(dataSourceProxy);
18 sqlSessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mapper/*.xml"));
19 sqlSessionFactoryBean.setTransactionFactory(new SpringManagedTransactionFactory());
20 return sqlSessionFactoryBean.getObject();
21 }
22}
微服务代码编写
订单服务具体实现:
1@Service
2@Slf4j
3public class OrderServiceImpl implements OrderService {
4 @Override
5 @GlobalTransactional(name = "jzh-create", rollbackFor = Exception.class)
6 public void create(Order order) {
7 log.info("************开始创建订单");
8 orderDao.create(order);
9
10 log.info("************开始扣库存");
11 storageService.decrease(order.getProductId(), order.getCount());
12 log.info("************完成扣库存");
13
14 log.info("************开始扣钱");
15 accountService.decrease(order.getUserId(), order.getMoney());
16 log.info("************扣钱完成");
17
18 orderDao.update(order.getUserId(), 0);
19 log.info("************订单完成");
20 }
21
22 @Resource
23 private OrderDao orderDao;
24 @Resource
25 private StorageService storageService;
26 @Resource
27 private AccountService accountService;
28}
rollbackFor 指定为任何异常发生都回滚。
其他两个微服务通过 feign 调用:
1// AccountService.java
2
3@FeignClient(value = "seata-account-service")
4public interface AccountService {
5 @PostMapping(value = "/account/decrease")
6 CommonResult decrease(@RequestParam("userId") Long userId,
7 @RequestParam("money") BigDecimal money);
8}
9
10// StorageService.java
11@FeignClient(value = "seata-storage-service")
12public interface StorageService {
13 @PostMapping(value = "/storage/decrease")
14 CommonResult decrease(@RequestParam("productId") Long productId,
15 @RequestParam("count") Integer count);
16}
通过 /order/create 接口请求服务:
1// OrderController.java
2
3@RestController
4@Slf4j
5public class OrderController {
6 @Resource
7 private OrderService orderService;
8
9 @PostMapping("/order/create")
10 public CommonResult create(@RequestBody Order order) {
11 log.info(order.toString());
12 orderService.create(order);
13 return new CommonResult(200, "订单创建成功");
14 }
15}
测试
- 访问
localhost:8848/nacos,发现三个微服务和 seata 服务都已经注册成功; - 发送
localhost:2001/order/create请求(POST,请求体为订单信息),返回 200,查看数据库表,数据变更正确; - 手动给 Account 服务添加异常,重复如上请求,返回 500,后台报异常,查看库存数据库表,发现存量没有变化,证明回滚成功。
容错机制:服务熔断
基本思想
应对微服务雪崩效应的一种链路保护机制,类似保险丝。
关于雪崩效应:
微服务之间的数据交互是通过远程调用来完成的。服务 A 调用服务,服务 B 调用服务 C,某一时间链路上对服务 C 的调用响应时间过长或者服务 C 不可用,随着时间的增长,对服务 C 的调用也越来越多,然后服务 C 崩溃了,但是链路调用还在,对服务 B 的调用也在持续增多,然后服务 B 崩溃,随之 A 也崩溃,导致雪崩效应。
实现机制
当某服务出现不可用或响应超时的情况时,为了防止整个系统出现雪崩,暂时停止对该服务的调用。
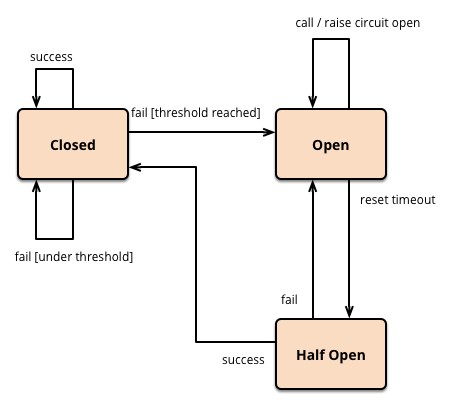
通过 Hystrix 实现服务熔断,Hystrix 会监控微服务间调用的状况,当失败的调用到一定阈值,就会启动熔断机制,断路器打开。而在一段时间之后,断路器会变为半开状态,此时允许部分微服务调用,如果都成功了,即不超过设定好的阈值,那么断路器将恢复为关闭状态。
如下图所示:(来自Martin Fowler大神的博客)
Hystrix 实践
这里实现一下服务监控和熔断。
依赖导入
1<!-- 服务熔断 -->
2<dependency>
3 <groupId>org.springframework.cloud</groupId>
4 <artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
5</dependency>
6<dependency>
7 <groupId>org.springframework.cloud</groupId>
8 <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
9</dependency>
10
11<!-- 服务监控 -->
12<dependency>
13 <groupId>org.springframework.cloud</groupId>
14 <artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
15</dependency>
基本配置
启动类添加 @EnableHystrix 注解,表示使用熔断器,添加 @EnableHystrixDashboard 注解,表示使用监控面板。
在要监控的服务的配置文件中添加:
1# hystrix 9001 监控配置
2management:
3endpoints:
4 web:
5 exposure:
6 include: hystrix.stream, info, health
方法实现
1// PaymentService.java
2public interface PaymentService {
3 ...
4 String circuitBreaker(Integer id);
5}
在实现类设置服务熔断的核心配置:
1// (1)启用断路器:
2@HystrixProperty(name = "circuitBreaker.enabled", value = "true")
3
4// (2)设置请求次数:
5@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "10")
6
7// (3)设置时间窗口期:
8@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds", value = "10000")
9
10// (4)设置失败率:
11@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "60")
如上设置的值,如果在 10 秒内,失败率达到请求次数(10)的百分之 60,也就是 6 次,就会打开断路器,否则断路器依然关闭。
断路器打开后,在一定时间之后,断路器变为半开状态,允许部分请求访问,如果这些请求满足要求,不超阈值,则断路器恢复为关闭状态。
1@Service
2public class PaymentServiceImpl implements PaymentService {
3 ...
4 @Override
5 @HystrixCommand(fallbackMethod = "circuitBreaker_fallback",
6 commandProperties = {
7 @HystrixProperty(name = "circuitBreaker.enabled", value = "true"),
8 @HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "10"),
9 @HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds", value = "10000"),
10 @HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "60")
11 })
12 public String circuitBreaker(Integer id) {
13 if (id < 0) throw new RuntimeException("id 不能小于0");
14 String uuid = IdUtil.simpleUUID();
15 return Thread.currentThread().getName() + "\t" + "uuid:" + uuid;
16 }
17 public String circuitBreaker_fallback(@PathVariable("id") Integer id) {
18 return "id 不能小于0, 请重试~ id: " + id;
19 }
20}
接着编写接口:
1// PaymentController.java
2@RestController
3@Slf4j
4public class PaymentController {
5 @Resource
6 private PaymentService paymentService;
7
8 @GetMapping("/payment/cir/{id}")
9 public String paymentCircuitBreaker(@PathVariable("id") Integer id) {
10 return paymentService.circuitBreaker(id);
11 }
12 ...
测试
- 打开:
http://{ip}:{port}/hystrix; - 监控:
http://{ip}:{port}/actuator/hystrix.stream; - 访问
http://localhost:8001/payment/cir/1,可以正常访问; - 多次访问
http://localhost:8001/payment/cir/-1, 返回系统繁忙信息,发现断路器开启了: - 此时,再访问
http://localhost:8001/payment/cir/1,发现返回了系统繁忙信息; - 多次访问
http://localhost:8001/payment/cir/1,发现断路器关闭,恢复正常访问。
容错机制:服务降级
基本思想
服务降级是指在服务器压力剧增的时候,根据实际业务使用情况以及流量,对一些服务和页面有策略的不处理或者用一种简单的方式进行处理,从而释放服务器资源的资源以保证核心业务的正常高效运行。
多用于微服务架构中,一般当整个微服务架构整体的负载超出了预设的上限阈值(和服务器的配置性能有关系),或者即将到来的流量预计会超过预设的阈值时。
实现机制
为了预防某些功能出现负荷过载或者响应慢的情况,在其内部暂时舍弃对一些非核心的接口和数据的请求,而直接返回一个提前准备好的 fallback(退路)错误处理信息。
这样,虽然提供的是一个有损的服务,但却保证了整个系统的稳定性和可用性。
Hystrix 实践
本实践配合了 Feign 实现,利用 Feign 通过接口的方式解耦服务这一特点,通过在实现服务接口的类来编写方法对应的 fallback 方法。
依赖导入
在消费方实现服务降级,除了基本包导入外,导入以下:
1<dependency>
2 <groupId>org.springframework.cloud</groupId>
3 <artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
4</dependency>
5<dependency>
6 <groupId>org.springframework.cloud</groupId>
7 <artifactId>spring-cloud-starter-openfeign</artifactId>
8</dependency>
9<dependency>
10 <groupId>org.springframework.cloud</groupId>
11 <artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
12</dependency>
基本配置
1# 设置feign超时时间(默认为1秒)
2feign:
3hystrix:
4 enabled: true
5client:
6 config:
7 default:
8 ConnectTimeOut: 5000
9 ReadTimeOut: 5000
10# 设置hystrix超时时间(默认为1秒)
11hystrix:
12command:
13 default:
14 execution:
15 isolation:
16 thread:
17 timeoutInMilliseconds: 2000
其他关于 Feign 的环境配置省略了。
方法实现
在使用了 Feign 的基础上使用 Hystrix 功能,指定 fallback 对应的实现类。
1// PaymentService.java
2@Service
3@FeignClient(value = "CLOUD-HYSTRIX-PAYMENT-SERVICE", fallback = PaymentHystrixService.class)
4public interface PaymentService {
5 // ...
6 @GetMapping("/payment/tt")
7 CommonResult<Object> timeoutTest();
8}
9
10// PaymentServiceImpl.java
11@Service
12public class PaymentHystrixService implements PaymentService {
13 // ...
14 @Override
15 public CommonResult<Object> timeoutTest() {
16 return new CommonResult<>(500, "error");
17 }
18}
接着编写接口:
1// PaymentController.java
2@RestController
3@Slf4j
4public class PaymentController {
5 @Resource
6 private PaymentService paymentService;
7 ...
8 /**
9 * @description: 访问一个耗时超过3秒的服务
10 * @author Jiang Zhihang
11 * @date 2022/7/26 11:16
12 */
13 @GetMapping("/consumer/payment/tt")
14 public CommonResult<Object> timeoutTest() {
15 return paymentService.timeoutTest();
16 }
17}
测试
一、访问 http://localhost:8001/payment/tt,由于 hystrix 配置最小超时时间为 2 秒,而访问时间超 3 秒,所以得到如下结果:
1{
2 "code": 500,
3 "message": "error",
4 "data": null
5}
可以发现调用了 fallback 方法。
二、修改 hystrix 超时时间为 4 秒,再次访问得到:
1{
2 "code": 200,
3 "message": "timeout test",
4 "data": null
5}
得到成功返回的数据。
容错机制:服务限流
实现目标
当系统的处理能力不能应对外部请求的突增流量时,为了不让系统奔溃,必须采取限流的措施。限流目标:
- 防止被突发流量冲垮
- 防止恶意请求和攻击
- 保证集群服务中心的健康稳定运行(流量整形)
- API 经济的细粒度资源量(请求量)控制
限流算法
- 计数限流算法
- 固定窗口限流算法(采样时间窗)
- 滑动窗口限流(记录每个请求到达的时间点)
- 漏桶算法(定速流出):宽进严出,按照固定速率处理
- 令牌桶算法(定速流入):每个请求分配一个令牌,只有拿到了令牌才能进入服务器处理
容错机制:Sentinel
通过 Sentinel 同时完成实现服务熔断、降级和限流。
基本概念
Sentinel 是面向分布式、多语言异构化服务架构的流量治理组件,主要以流量为切入点,从流量路由、流量控制、流量整形、熔断降级、系统自适应过载保护、热点流量防护等多个维度来帮助开发者保障微服务的稳定性。
架构说明
两个生产者服务运行在 9001 和 9002 端口,一个消费者服务运行在 80 端口,均注册到 nacos,消费者调用两个生产者的服务。
将消费者服务注册到 sentinel 中,通过修改一些规则进行测试:
- controller 下的方法指定好处理服务限流,降级或熔断等的方法 blockHandler,以及处理未知异常的 fallback 方法,通过指定 class 的方法避免代码膨胀。
- service 下的方法指定好关于生产者的服务限流,降级或熔断等的处理方法。
代码实现(生产者端)
基本配置
关于 nacos 的配置省略,只记录 sentinel 的配置:
1spring:
2 application:
3 name: nacos-payment-provider
4 cloud:
5 sentinel:
6 transport:
7 dashboard: localhost:8080
8 port: 8179
方法实现
返回对应端口,方便测试负载均衡:
1@RestController
2@Slf4j
3public class PaymentController {
4 @Value("${server.port}")
5 private String port;
6
7 @GetMapping("/payment/nacos/info")
8 public String paymentInfo() {
9 return "port: " + port;
10 }
11}
代码实现(消费者端)
依赖导入
1<dependency>
2 <groupId>com.alibaba.cloud</groupId>
3 <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
4</dependency>
基本配置
注意要开启 feign 的 sentinel 支持:
1spring:
2 application:
3 name: nacos-order-consumer
4 sentinel:
5 transport:
6 dashboard: localhost:8080
7 port: 8179
8feign:
9 sentinel:
10 enabled: true
方法实现
1@FeignClient(value = "nacos-payment-provider", fallback = PaymentFallbackService.class)
2@Service
3public interface PaymentService {
4 @GetMapping("/payment/nacos/info")
5 String paymentInfo();
6}
对应实现类:
1@Service
2public class PaymentFallbackService implements PaymentService{
3 @Override
4 public String paymentInfo() {
5 return "feign::fallback";
6 }
7}
这里处理关于生产者的服务限流,降级或熔断问题。
两个服务问题 Hanlder 的编写。根据官方文档,这里的方法都需指明为 static,否者无法识别:
1@Component
2public class GlobalBlockHandler {
3 public static String block1(BlockException e) {return "block1";}
4 public static String block2(BlockException e) {return "block2";}
5}
这个用于消费者端处理服务限流,降级或熔断等问题。
1@Component
2public class GlobalFallbackHandler {
3 public static String fallback1() {return "fallback1";}
4 public static String fallback2() {return "fallback2";}
5}
这个用于消费者端处理未知异常。
最后编写 controller,指定处理方式:
1@RestController
2@Slf4j
3public class OrderController {
4 @Resource
5 PaymentService paymentService;
6
7 @GetMapping("/consumer/payment/nacos/info")
8 @SentinelResource(
9 value = "paymentInfo",
10 fallbackClass = GlobalFallbackHandler.class, fallback = "fallback1",
11 blockHandlerClass = GlobalBlockHandler.class, blockHandler = "block1"
12 )
13 public String paymentInfo() {
14 int a = 1 / 0;
15 return paymentService.paymentInfo();
16 }
17}
指定好 class 的同时,需用 fallback 和 blockHandler 分别指定好具体的方法名。
测试
- 测试除 0 错误是否正确进入 fallback1:直接访问接口,返回 “fallback1”,正确;
- 测试消费者端服务限流:sentinel 指定流控规则,QPS 设置阈值为 1,连续访问接口,返回 “block1”,正确;
- 测试生产者端除 0 错误是否正确进入 fallback:给生产者 controller 添加除 0 错误,访问接口,返回 “feign::fallback”,正确;
- 测试其他服务规则:指定熔断规则,熔断策略选为慢调用比例,最大 RT(Round Trip Time,也叫响应时间)设置为 200ms,比例阈值设置为 0.5,最小请求数设置为 5。为模拟慢调用,手动增大发出接口请求到收到结果的延迟,在 controller 中添加
Thread.sleep(1000),延迟 1 秒:连续访问接口,首先返回了“9001”,即访问正常时得到的结果,然而发现在 5 次以上的请求以后,返回了 “block1”,成功熔断。
分布式一致性协议
2PC
TODO
Paxos
TODO
Raft
云原生
Docker
TODO
K8S
TODO