Redis 重要操作和知识汇总
连接与配置
1# 启动 redis
2redis-server
3# 连接到本地 redis:
4redis-cli
5# 连接到远程 redis:
6redis-cli -h host -p port -a password
7# 获取配置
8config get 配置名
9# 配置
10config set 配置名 值
11# 获取密码
12config get requirepass
13# 设置密码
14config set requirepass 12345
15# 进行密码验证
16auth 12345
17OK
ps: 如果重启服务密码会失效, 通过修改配置文件可以解决:
1# redis.conf
2requirepass ${password}
以后通过下面命令启动服务,这样就可以在服务开启时同时指定密码。
1redis-server redis.conf
数据类型
string
1127.0.0.1:6379> set mkey sos
2OK
3127.0.0.1:6379> get mkey
4"sos"
5127.0.0.1:6379> del mkey
6(integer) 1
7127.0.0.1:6379> get mkey
8(nil)
list
list:
1lpush clist redis
2lpush clist mysql
3lrange clist 0 100
hash
mkeys: 接偶数个参数,一一对应。
1127.0.0.1:6379> hmset mkeys A a B b C c
2OK
3127.0.0.1:6379> hget mkeys B
4"b"
set
1127.0.0.1:6379> sadd mkey 123
2(integer) 1
3127.0.0.1:6379> sadd mkey 123
4(integer) 0
5127.0.0.1:6379> smembers mkey
61) "123"
zset(sorted_set)
根据分数和字典序进行排序,同分数下比较字典序,不同分数时,分数越低越靠前。
1# ... {分数} {键值}
2127.0.0.1:6379> zadd zs 1 ak
3(integer) 1
4127.0.0.1:6379> zadd zs 1 to
5(integer) 1
6127.0.0.1:6379> zrangebyscore zs 0 100
71) "ak"
82) "to"
9127.0.0.1:6379> zadd zs 0 pp
10(integer) 1
11127.0.0.1:6379> zrangebyscore zs 0 100
121) "pp"
132) "ak"
143) "to"
批量操作
涉及批量获取和删除操作的, 线上不建议使用。
1# 批量删除匹配到的 key
2redis-cli keys "user-*" | xargs redis-cli del
3# 如果设置了密码:
4# redis-cli -a "pwd" keys "user-*" | xargs redis-cli -a "pwd" del
5
6# 批量获取匹配到的 key 对应的 value
7redis-cli keys user-* | xargs redis-cli mget
8
9# 根据pattern获取key
10# - * 代表匹配任意字符
11# - ? 代表匹配一个字符
12# - [] 代表匹配部分字符,例如[1,3]代表匹配1和3,而[1-10]代表匹配1到10的任意数字。
13# - x 转移字符,例如要匹配星号,问号需要转义的字符
14keys {pattern}
15## e.g.
16127.0.0.1:6379> keys m*
171) "mkeys"
182) "mkey"
19
20# 获取key数量
21127.0.0.1:6379> dbsize
22
23# 删除所有数据库所有key
24127.0.0.1:6379> flushall
25# 删除当前数据库所有key
26127.0.0.1:6379> flushdb
事务
1127.0.0.1:6379> multi # 开启事务
2OK
3127.0.0.1:6379> set book java
4QUEUED
5127.0.0.1:6379> get book
6QUEUED
7127.0.0.1:6379> exec # 执行事务
81) OK
92) "java"
10127.0.0.1:6379> get book
11"java"
12127.0.0.1:6379> multi
13OK
14127.0.0.1:6379> set name peter
15QUEUED
16127.0.0.1:6379> discard # 取消事务
17OK
18127.0.0.1:6379> exec
19(error) ERR EXEC without MULTI
20127.0.0.1:6379> get name
21(nil)
发布和订阅
1127.0.0.1:6379> subscribe news
2Reading messages... (press Ctrl-C to quit)
31) "subscribe"
42) "news"
53) (integer) 1
1# 另一个 redis 连接下
2127.0.0.1:6379> publish news "hello"
3(integer) 1
4127.0.0.1:6379> publish news "world"
5(integer) 1
在前一个 redis-cli 中可接收到订阅的消息:
1127.0.0.1:6379> subscribe news
2Reading messages... (press Ctrl-C to quit)
31) "subscribe"
42) "news"
53) (integer) 1
61) "message"
72) "news"
83) "hello"
91) "message"
102) "news"
113) "world"
过期删除策略和内存淘汰策略
Redis 使用的过期删除策略是「惰性删除+定期删除」,删除的对象是已过期的 key。

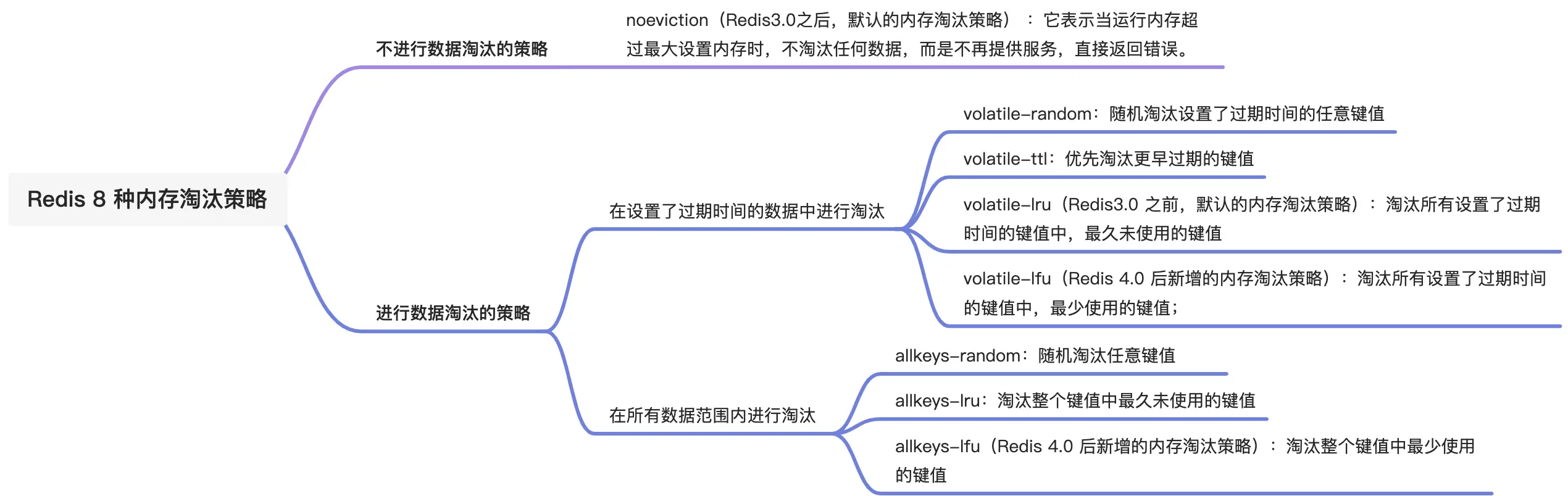
内存淘汰策略是解决内存过大的问题,当 Redis 的运行内存超过最大运行内存时,就会触发内存淘汰策略,Redis 4.0 之后共实现了 8 种内存淘汰策略,我也对这 8 种的策略进行分类,如下:
String 底层实现 SDS
SDS 对 c 原始 char 数组的改进:
- 支持扩容
- 包含长度 len,获取长度复杂度 O(1)
- 空间预分配
- 惰性空间释放
惰性空间释放用于优化 SDS 的字符串缩短操作: 当 SDS 的 API 需要缩短 SDS 保存的字符串时, 程序并不立即使用内存重分配来回收缩短后多出来的字节, 而是使用 free 属性将这些字节的数量记录起来, 并等待将来使用。
持久化的方式
RDB
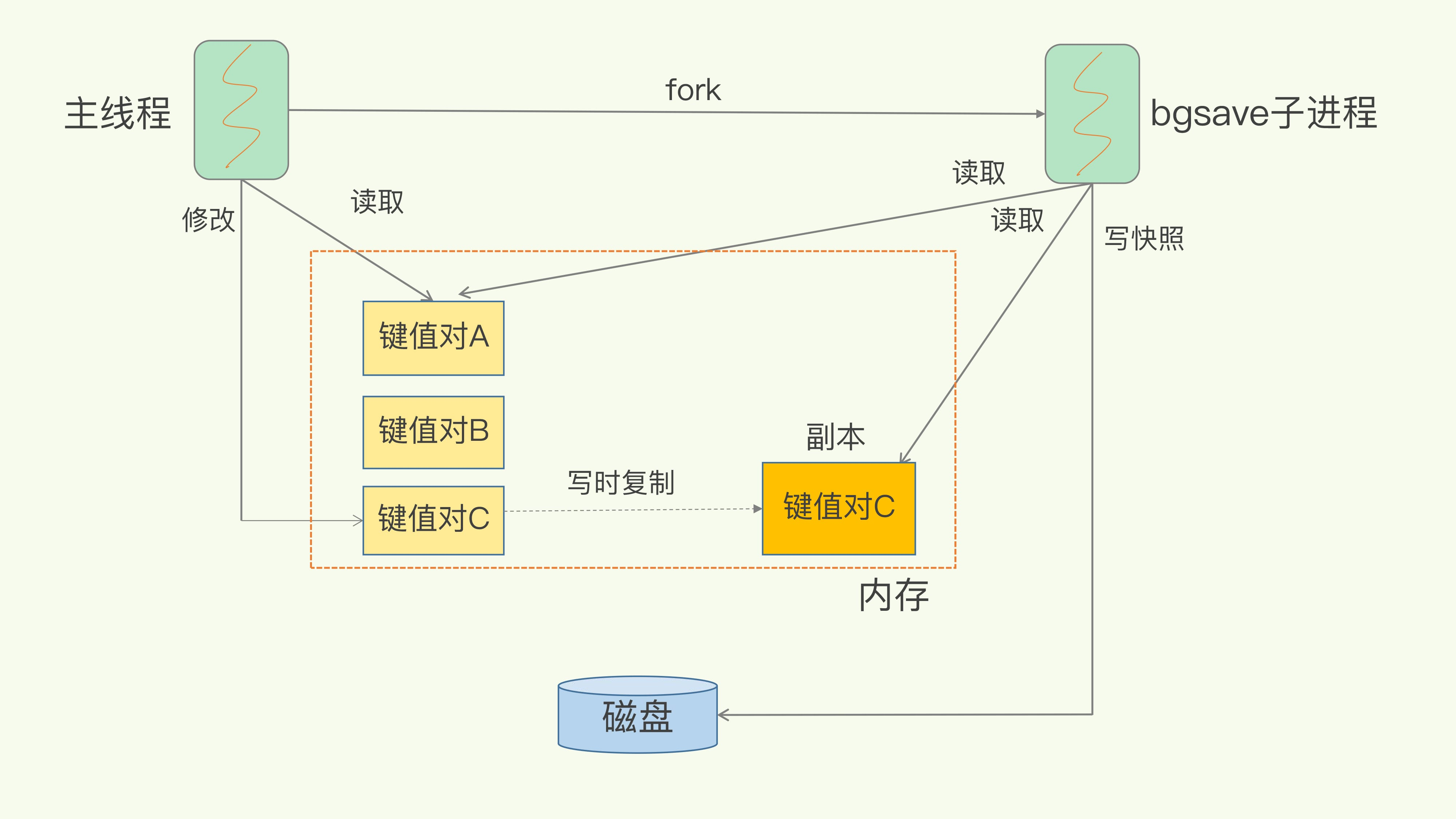
RDB(Redis DataBase), 中文名为快照/内存快照,RDB 持久化是把当前进程数据生成快照保存到磁盘上的过程。触发 rdb 持久化的方式有 2 种,分别是手动触发和自动触发。
手动触发:save & bgsave
- save:阻塞当前 Redis 服务器,直到 RDB 过程完成为止
- bgsave:Redis 进程执行 fork 操作创建子进程,RDB 持久化过程由子进程负责,完成后自动结束。
自动触发:4 种情况
- 配置:redis.conf 中配置 save m n,即在 m 秒内有 n 次修改时,自动触发 bgsave 生成 rdb 文件
- 主从复制时,从节点要从主节点进行全量复制时也会触发 bgsave 操作,生成当时的快照发送到从节点
- 执行 debug reload 命令重新加载 redis 时也会触发 bgsave 操作
- 默认情况下执行 shutdown 命令时,如果没有开启 aof 持久化,那么也会触发 bgsave 操作
RDB 持久化时如何保证数据一致性?
RDB 中的核心思路是 Copy-on-Write,来保证在进行快照操作的这段时间,需要压缩写入磁盘上的数据在内存中不会发生变化。在正常的快照操作中,一方面 Redis 主进程会 fork 一个新的快照进程专门来做这个事情,这样保证了 Redis 服务不会停止对客户端包括写请求在内的任何响应。另一方面这段时间发生的数据变化会以副本的方式存放在另一个新的内存区域,待快照操作结束后才会同步到原来的内存区域。
AOF
Redis 是“写后”日志,Redis 先执行命令,把数据写入内存,然后才记录日志。日志里记录的是 Redis 收到的每一条命令,这些命令是以文本形式保存。
AOF 持久化过程
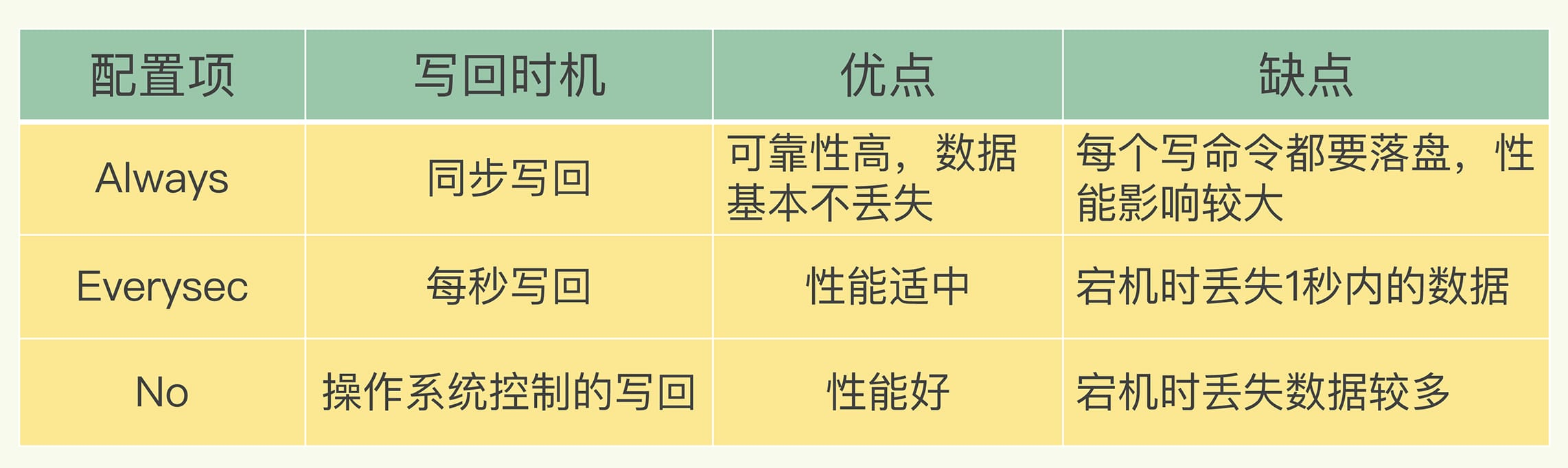
- 命令追加:服务器在执行完一个写命令之后,会以协议格式将被执行的写命令追加到服务器的 aof_buf 缓冲区
- 文件写入和同步:有三种策略如下
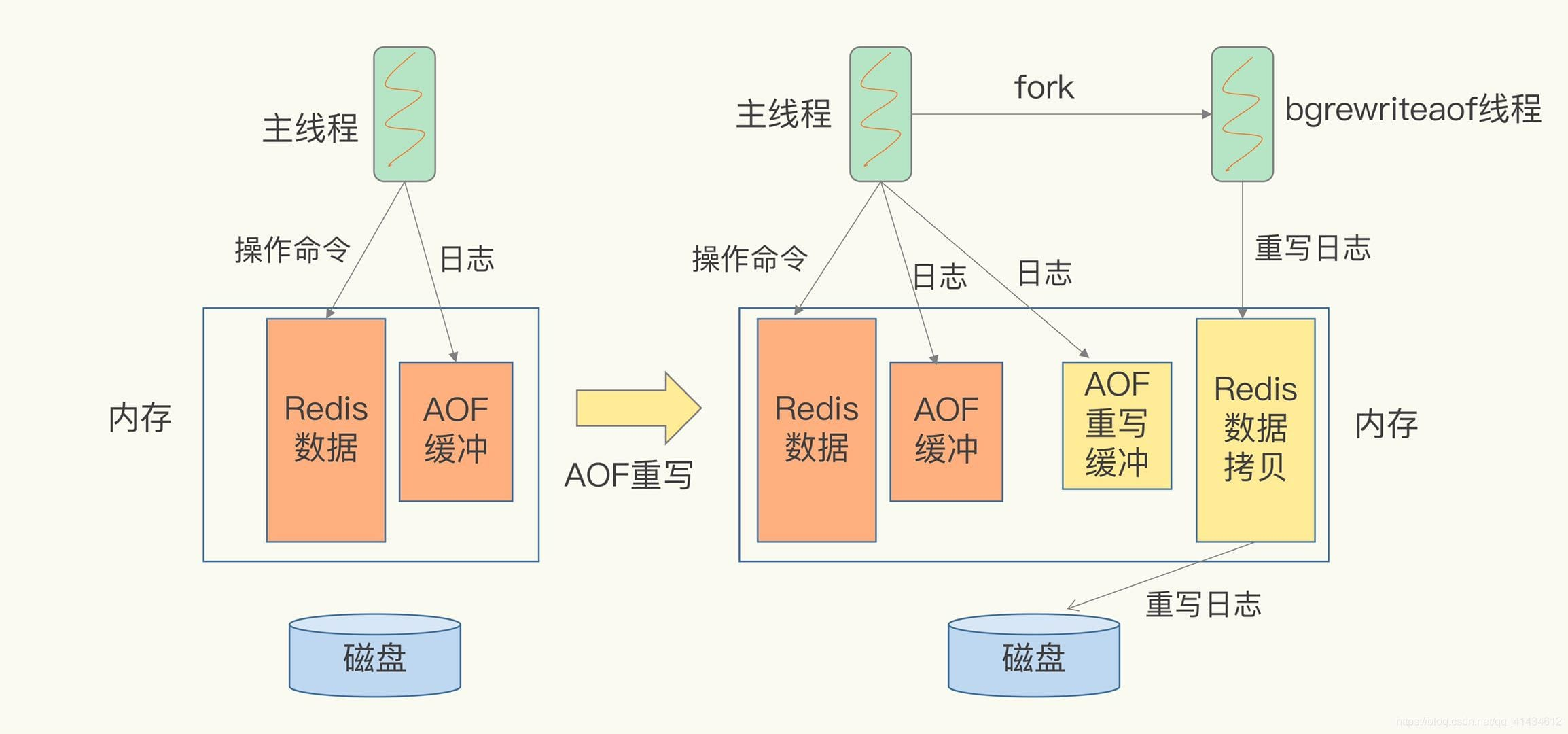
AOF 重写机制
AOF 持久化会记录每个写命令到 AOF 文件,随着时间越来越长,AOF 文件会变得越来越大。如果不加以控制,会对 Redis 服务器,甚至对操作系统造成影响,而且 AOF 文件越大,数据恢复也越慢。为了解决 AOF 文件体积膨胀的问题,Redis 提供 AOF 文件重写机制来对 AOF 文件进行“瘦身”。
实例:
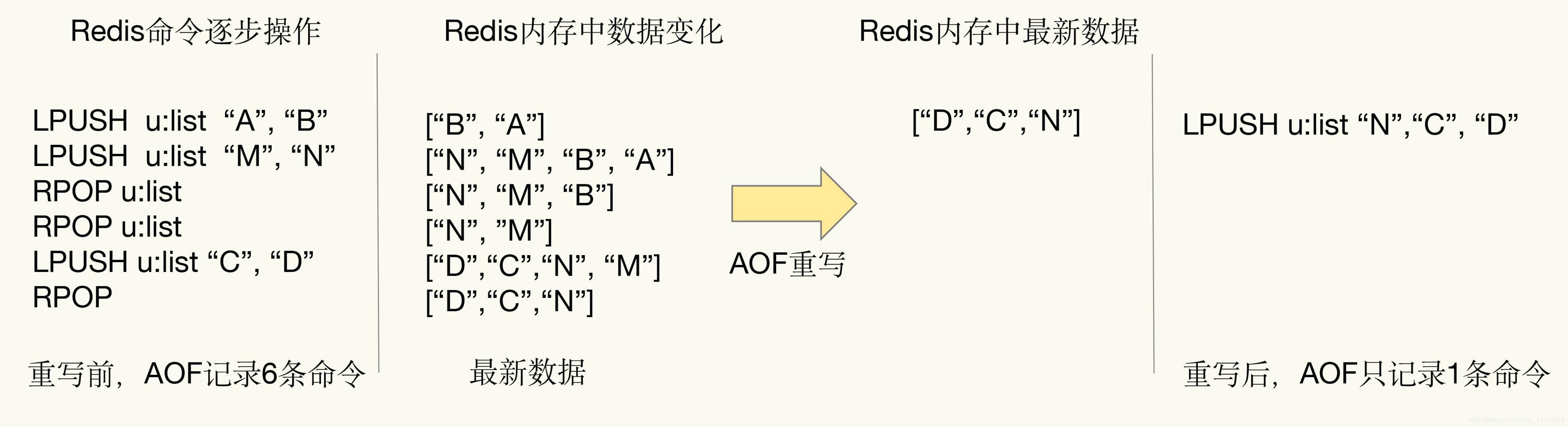
操作过程:
RDB + AOF
Redis 4.0 中提出了一个混合使用 AOF 日志和内存快照的方法。简单来说,内存快照以一定的频率执行,在两次快照之间,使用 AOF 日志记录这期间的所有命令操作。
Q: 两者都存在,如何从持久化恢复数据?
A: 优先使用 AOF 文件,如果不存在则使用 RDB。
Redis 为什么是单线程的
原因在于 redis 用单个 CPU 绑定一块内存的数据,然后针对这块内存的数据进行多次读写的时候,都是在一个 CPU 上完成的。
redis 核心就是如果我的数据全都在内存里,我单线程的去操作就是效率最高的。所以,redis 是单线程。
Redis 和 MySQL 数据如何保持数据一致
第一种方案:采用延时双删+设置缓存过期时间策略
- 先删除缓存
- 再写数据库
- 休眠 500 毫秒
- 再次删除缓存
删除缓存可能失败,所以需要设置过期时间。休眠时间一定长度上保证读到写完数据库后的数据。
第二种方案:异步更新缓存(基于订阅 binlog 的同步机制)
技术方案:MySQL binlog 增量订阅消费+消息队列+增量数据更新到 redis。
- 读 Redis:热数据基本都在 Redis
- 写 MySQL: 增删改都是操作 MySQL
- 更新 Redis 数据:MySQL 的数据操作 binlog,来更新到 Redis
解决 Redis 大 key 问题
定位大 key:
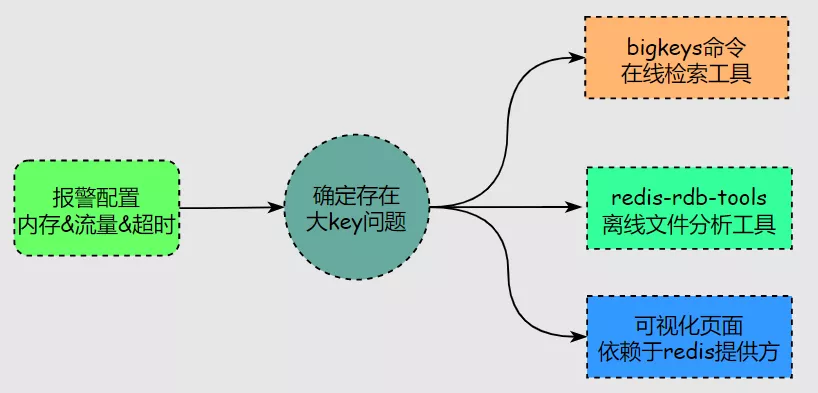
ps: redis-cli --bigkeys 以遍历的方式分析 Redis 实例中的所有 Key,并返回整体统计信息与每个数据类型中 Top 前几的大 Key。
删除或优化大 key:
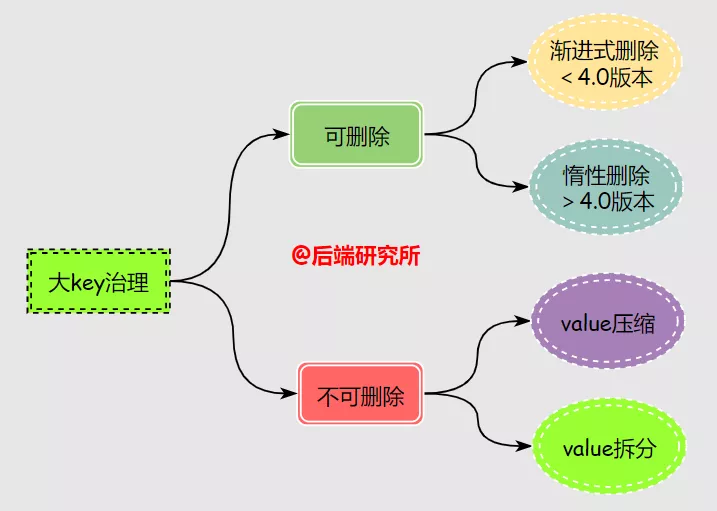
Redis 数据结构
如下表所示:

附: zset 底层数据结构
zset 使用了 2 种数据结构,分别是 zipList(压缩列表)和 skipList(跳跃列表)。
当 zset 满足以下条件时使用压缩列表, 否则使用跳跃列表
- 成员的数量小于 128 个;
- 每个 member(成员)的字符串长度都小于 64 个字节。
参考: