大数据相关知识及实践整理汇总
TOC
- TOC
- Preface
- Nouns
- Hadoop
- Spark
- Flink
- LSM
- Kafka
- Hive
- HBase
- Paimon
- Hudi
- ClickHouse
- MPP
- StarRocks
- BitMap
- Blogs
- Reference
Preface
最近在负责 ShopeePay 大数据处理相关的工作,发现对大数据相关知识认识还不够,只凭大学相关课程显然差的远,在一些技术设计上存在一定问题。同时在 Shopee 对账项目中也了解到大数据领域包括 paimon 在内的流批统一相关的前沿技术,知之甚少,需要恶补一下。
这里将对大数据相关的知识做一个整理汇总,主要包括 Hadoop、Spark、Flink、Kafka 等组件的重要概念、架构、基础用法,此外还简单记录了在 Shopee DataStudio 中的 Best Practice。后面持续补充更多应用场景、踩过的坑和更多原理性的知识。
Nouns
- SLA(Service-Level Agreement):服务等级协议,指的是系统服务提供者对客户的一个服务承诺,用于衡量大型“分布式“系统是否健康的协议。
- OLAP(Online Analytical Processing):联机分析处理,主要用途是分析聚合数据。
- OLTP(Online Transaction Processing):联机事务处理,主要用途是处理数据库事务。
- HTAP(Hybrid Transactional/Analytical Processing):混合事务/分析处理。
- DQC(Data Quality Control):数据质量监控,对数据库里的数据质量进行质量管理的工具。
- SPM(Shopping Page Mark):导购页面标记,是电商业务为内外站提供的一套跟踪成交效果数据的解决方案,根据 SPM 效果指标和数据可以得到 PV、UV、CVR 等数据。SPM 编码是用来跟踪界面模块位置的编码,标准编码由 4 段组成,采用 a.b.c.d 段格式。
- PV(Page View):页面浏览量。
- UV(Unique Visitors):独立访客。
- GMV(Gross Merchandise Volume):商品交易总额。
- CVR(Conversions Rates):转化率,网站转化率=进行了相应的动作的访问量/总访问量。
- KYC(Know Your Customer):意思是充分了解你的客户,是指在服务商和客户进行业务往来之前或期间核实客户身份的过程。
- ETL(Extract-Transform-Load):用于描述将数据从来源端经过抽取、转换、加载到目的端的过程。
- ODS(Operation Data Store):数据运营层,是数据准备区。数据源中的数据经过 ETL 过程之后进入本层。
- DW(Data Warehouse):数据仓库。数据仓库从上到下可以分为三个层:DWD、DWM、DWS。
- DWD(Data Warehouse Details):数据细节层,该层是业务层和数据仓库的隔离层,对 ODS 数据层做一些数据的清洗和规范化的操作。
- DWM(Data Warehouse Middle):数据中间层,对通用的核心维度进行聚合操作,算出相应的统计指标。
- DWS(Data Warehouse Service):数据服务层,基于 DWM 上的基础数据,整合汇总成分析某一个主题域的数据服务层,一般是宽表,用于提供后续的业务查询,OLAP 分析,数据分发等。
- ADS(Application Data Service):数据应用层,出报表,该层主要是提供给数据产品和数据分析使用的数据。
- FT(Fact Table):事实表是指存储有事实记录的表,比如系统日志、销售记录等。
- DIM(Dimension Table):维度表,是与事实表相对应的一种表,它保存了维度的属性值,可以跟事实表做关联,相当于将事实表上经常重复出现的属性抽取、规范出来用一张表进行管理。
- WT(Wide Table):指字段比较多的数据库表。通常是指业务主体相关的指标、纬度、属性关联在一起的一张数据库表。
Hadoop
Apache Hadoop 软件是一个开源框架,支持使用简单的编程模型跨计算机集群对大型数据集进行分布式存储和处理。它的核心模块分为存储和计算模块,前者被称为 HDFS,后者即 MapReduce 计算模型。
HDFS
基本概念
HDFS,即 Hadoop 分布式文件系统,它具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。
HDFS 遵循主从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成。NameNode 负责执行有关文件系统命名空间的操作,还负责集群元数据的存储,记录着文件中各个数据块的位置信息。DataNode 负责提供来自文件系统客户端的读写请求,执行块的创建,删除等操作。
HDFS 提供了数据复制机制。HDFS 将每一个文件存储为一系列块,每个块由多个副本来保证容错,块的大小和复制因子可以自行配置(默认情况下,块大小是 128M,默认复制因子是 3)。
HDFS 提供了数据完整性校验机制来保证数据的完整性,创建 HDFS 文件时会计算文件每个块的校验和并将其存储在同一 HDFS 命名空间下。HDFS 还通过心跳机制和重新复制机制来确保 DataNode 的可用性。
采用操作
HDFS 采用 Shell 操作总结:
1# 显示当前目录结构
2hadoop fs -ls <path>
3# 创建目录
4hadoop fs -mkdir <path>
5# 删除文件
6hadoop fs -rm <path>
7# 递归删除目录和文件
8hadoop fs -rm -R <path>
9# 从本地加载文件到 HDFS
10hadoop fs -put [localsrc] [dst]
11# 从 HDFS 导出文件到本地
12hadoop fs -get [dst] [localsrc]
13# 查看文件内容
14hadoop fs -cat <path>
15# 拷贝文件
16hadoop fs -cp [src] [dst]
17# 移动文件
18hadoop fs -mv [src] [dst]
19# 统计当前目录下各文件大小
20# + 默认单位字节
21# + -s : 显示所有文件大小总和,
22# + -h : 将以更友好的方式显示文件大小(例如 64.0m 而不是 67108864)
23hadoop fs -du <path>
高可用原理
HDFS 的 HA,指的是在一个集群中存在多个 NameNode,分别运行在独立的物理节点上。在任何时间点,只有一个 NameNode 是处于 Active 状态,其它的是处于 Standby状态。 Active NameNode(简写为 Active NN)负责所有的客户端的操作,而 Standby NameNode(简写为 Standby NN)用来同步 Active NameNode 的状态信息,以提供快速的故障恢复能力。
MapReduce
MapReduce 是一个分布式计算框架,它的处理流程如下:
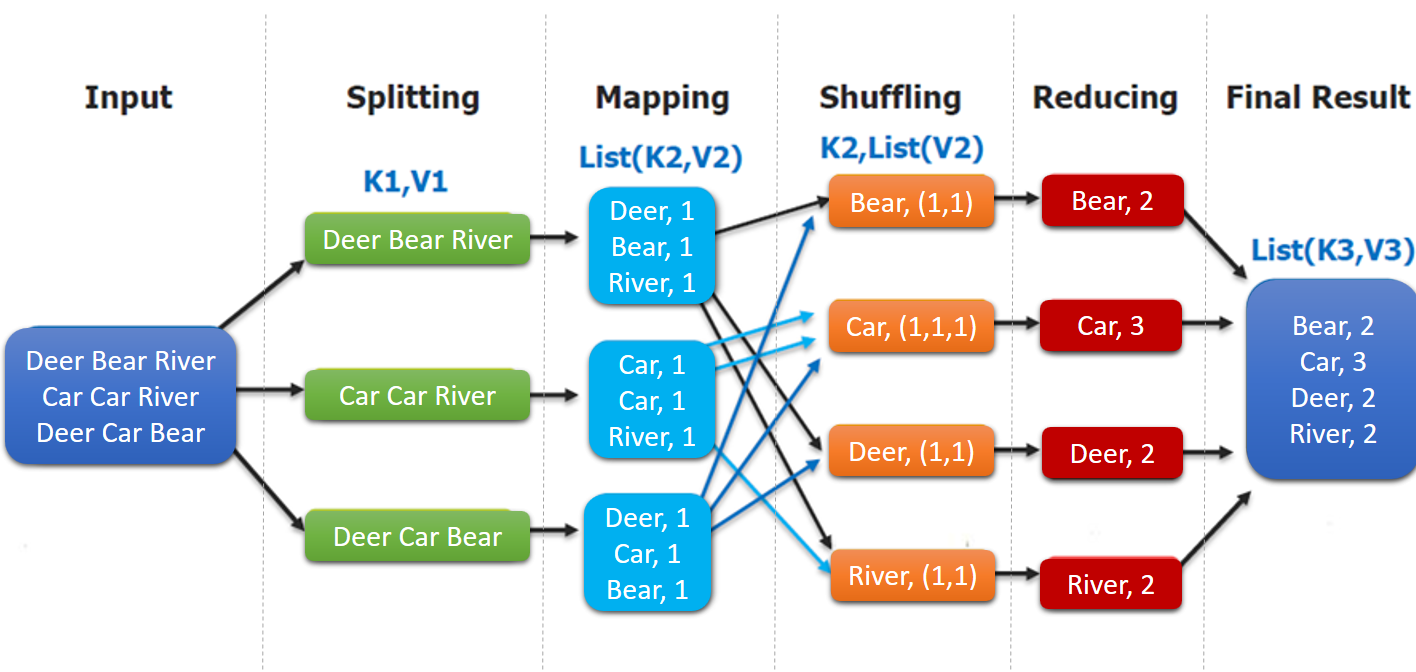
其中 splitting 和 shuffing 操作都是由框架实现的,需要我们自己编程实现的只有 mapping 和 reducing,这也就是 MapReduce 这个称呼的来源。
从上面流程中可以看到在 Mapping 到 Shuffling 的过程中存在大量的数据传输,可以使用 Combiner 在传输之前进行一个本地化的 Reduce 操作,降低数据传输量完成优化。注意这个优化手段需要注意是否影响最终结果,比如本地 Reduce 计算平均数将导致最终结果的错误。
还有一个重要的概念是 Partitioner,可以理解成分类器,将 map 的输出按照 key 值的不同分别分给对应的 reducer,默认的使用的是 HashPartitioner,对 key 值进行哈希散列并对 numReduceTasks 取余,可以自定义,比如按照单词分类,一个 java 示例如下:
1public class CustomPartitioner extends Partitioner<Text, IntWritable> {
2
3 public int getPartition(Text text, IntWritable intWritable, int numPartitions) {
4 return WordCountDataUtils.WORD_LIST.indexOf(text.toString());
5 }
6}
YARN
Apache YARN (Yet Another Resource Negotiator) 是 hadoop 2.0 引入的集群资源管理系统。用户可以将各种服务框架部署在 YARN 上,由 YARN 进行统一地管理和资源分配。
YARN 主要组件如下:
- ResourceManager:整个集群资源的主要协调者和管理者,负责给用户提交的所有应用程序分配资源;
- NodeManager:YARN 集群中的每个具体节点的管理者。主要负责该节点内所有容器的生命周期的管理,监视资源和跟踪节点健康。
- ApplicationMaster:在用户提交一个应用程序时,YARN 会启动一个轻量级的进程 ApplicationMaster。它负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器内资源的使用情况,同时还负责任务的监控与容错。
- Container:Container 是 YARN 中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。
YARN 工作原理大致如下:
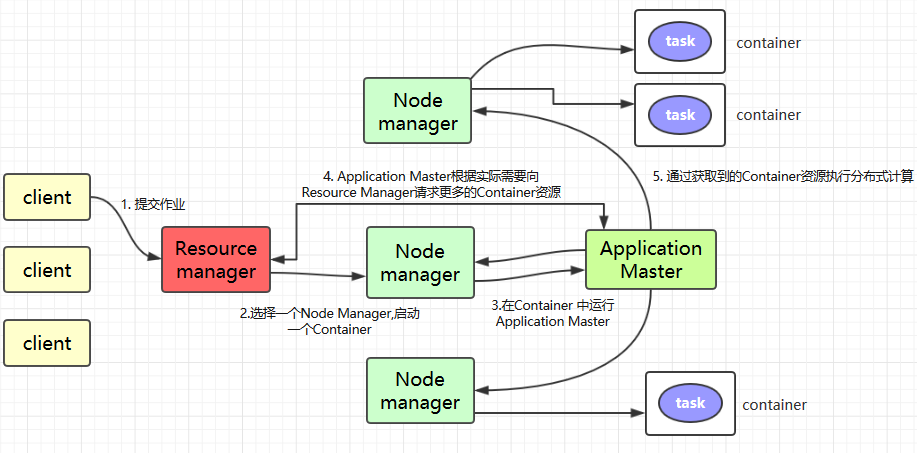
- Client 提交作业到 YARN 上;
- Resource Manager 选择一个 Node Manager,启动一个 Container 并运行 Application Master 实例;
- ApplicationMaster 根据实际需要向 Resource Manager 请求更多的 Container 资源;
- ApplicationMaster 通过获取到的 Container 资源执行分布式计算。
Spark
基本概念
Spark 基于 Spark Core 扩展了四个核心组件,分别用于满足不同领域的计算需求:
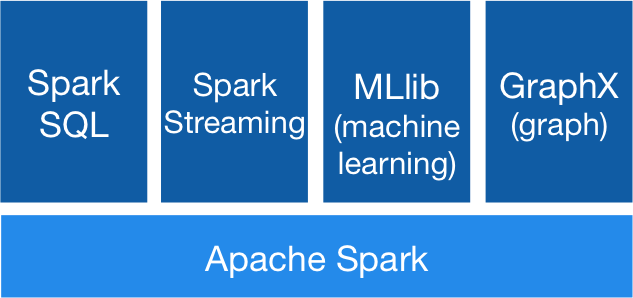
Spark 最基本的数据抽象是 RDD,全称为 Resilient Distributed Datasets(弹性分布式数据集),它是只读的、分区记录的集合,支持并行操作,可以由外部数据集或其他 RDD 转换而来。一个 RDD 由一个或者多个分区(Partitions)组成。
RDD 的一个重要特性是血缘关系。RDD 会保存彼此间的依赖关系,RDD 的每次转换都会生成一个新的依赖关系,这种 RDD 之间的依赖关系就像流水线一样。在部分分区数据丢失后,可以通过这种依赖关系重新计算丢失的分区数据,而不是对 RDD 的所有分区进行重新计算。RDD 血缘关系的依赖分为窄依赖和宽依赖。窄依赖是指父 RDD 的每个分区都只被子 RDD 的一个分区所使用,宽依赖是指父 RDD 的每个分区都被多个子 RDD 的分区所依赖。
基本操作
Spark 安装:
1# INSTALL
2wget https://dlcdn.apache.org/spark/spark-3.5.2/spark-3.5.2-bin-hadoop3.tgz
3tar -zxvf https://dlcdn.apache.org/spark/spark-3.5.2/spark-3.5.2-bin-hadoop3.tgz
4export SPARK_HOME="xxx/spark-3.5.2-bin-hadoop3"
5export PATH="$SPARK_HOME/bin:$PATH"
Spark 简单示例:
1# TEST
2spark-shell
3...
4Spark context Web UI available at http://10.53.32.147:4040
5Spark context available as 'sc' (master = local[*], app id = local-1724038257910).
6Spark session available as 'spark'.
7...
8
9# test map
10> sc.parallelize(List(1,2,3)).map(_ * 10).foreach(println)
11# test flapMap
12> sc.parallelize(List("spark flume spark", "hadoop flume hive")).flatMap(line => line.split(" ")).map(word=>(word,1)).reduceByKey(_+_).foreach(println)
13# test intersection
14> sc.parallelize(List(1, 2, 4, 5)).intersection(sc.parallelize(List(2, 4, 5, 6))).foreach(println)
15# test sortByKey
16> sc.parallelize(List((100, "hadoop"), (90, "spark"), (120, "storm"))).sortByKey(ascending = false).foreach(println)
Spark SQL 是 Spark 中的一个子模块,主要用于操作结构化数据,能够将 SQL 查询与 Spark 程序无缝混合,允许您使用 SQL 或 DataFrame API 对结构化数据进行查询。
为了支持结构化数据的处理,Spark SQL 提供了新的数据结构 DataFrame。DataFrame 是一个由具名列组成的数据集。如果你想使用函数式编程或者数据是非结构化的 (比如流媒体或者字符流),则使用 RDDs,否则出于性能上的考虑,应优先使用 DataFrame。Dataset 也是分布式的数据集合,在 Spark 1.6 版本被引入,它集成了 RDD 和 DataFrame 的优点。
一个简单的左外连接示例:
1empDF.join(deptDF, joinExpression, "left_outer").show()
2spark.sql("SELECT * FROM emp LEFT OUTER JOIN dept ON emp.deptno = dept.deptno").show()
Spark Streaming 是 Spark 的一个子模块,用于快速构建可扩展,高吞吐量,高容错的流处理程序。具有良好的容错性,Spark Streaming 支持快速从失败中恢复丢失的操作状态,能够和 Spark 其他模块无缝集成,将流处理与批处理完美结合,Spark Streaming 可以从多种数据源读取数据,也支持自定义数据源。
一个简单的单词计数示例:
1/*指定时间间隔为 5s*/
2val sparkConf = new SparkConf().setAppName("NetworkWordCount").setMaster("local[2]")
3val ssc = new StreamingContext(sparkConf, Seconds(5))
4
5/*创建文本输入流,并进行词频统计*/
6val lines = ssc.socketTextStream("hadoop001", 9999)
7lines.flatMap(_.split(" ")).map(x => (x, 1)).reduceByKey(_ + _).print()
8
9/*启动服务*/
10ssc.start()
11/*等待服务结束*/
12ssc.awaitTermination()
一个在 Shopee DataStudio 上执行 PySpark 用户自定义函数(UDF)任务的示例:
首先编辑 py 文件:
1# pyspark_udf_demo.py
2from pyspark.sql import SparkSession
3
4def add_udf(x):
5 return x + 2
6
7if __name__ == '__main__':
8 spark = SparkSession.builder.appName("add_udf").enableHiveSupport().getOrCreate()
9 sc = spark.sparkContext
10 sc.setLogLevel("WARN")
11 # register udf
12 spark.udf.register("test_add_udf", add_udf, 'int')
13 # use udf in sql
14 spark.sql("select test_add_udf(6)").show()
15 spark.stop()
接着创建 workflow,在 Resources 上传 pyspark_udf_demo.py 文件,然后创建任务,指定 py 文件和相关版本即可。
调优原则
Flink
基本概念
Flink 是一个分布式的流处理框架,它能够对有界和无界的数据流进行高效的处理。
Flink 的核心是流处理,当然它也能支持批处理,Flink 将批处理看成是流处理的一种特殊情况,即数据流是有明确界限的,这和 Spark Streaming 的思想是刚好相反。
Flink 核心架构如下:
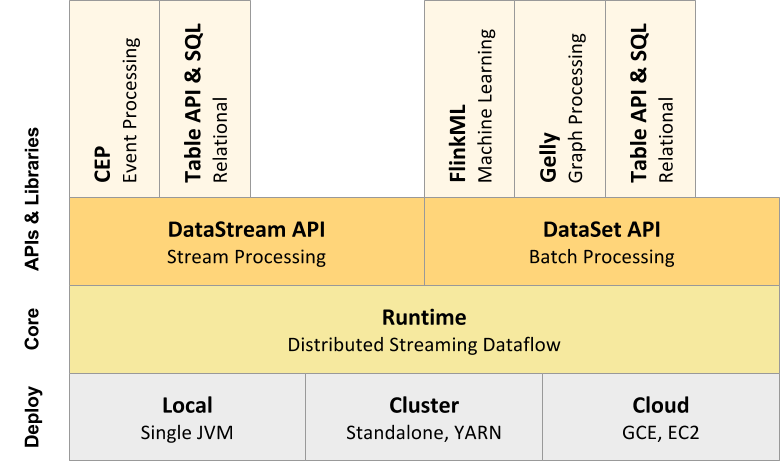
Flink 核心组件工作流程如下:
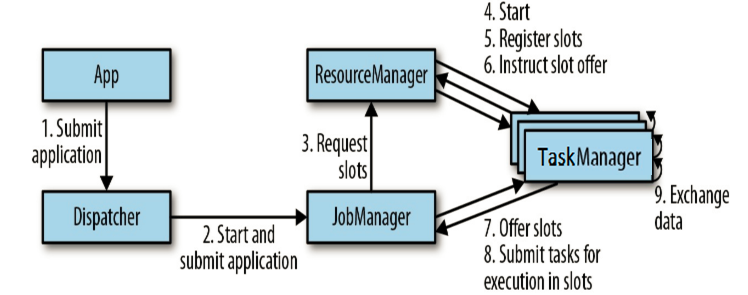
实践测试
Flink 快速测试使用:
1# INSTALL
2wget https://dlcdn.apache.org/flink/flink-1.20.0/flink-1.20.0-bin-scala_2.12.tgz
3tar -zxvf flink-1.20.0-bin-scala_2.12.tgz
4cd flink-1.20.0
5# TEST
6./bin/start-cluster.sh
7./bin/flink run examples/streaming/WordCount.jar
8tail tail log/flink-*-taskexecutor-*.out
9./bin/stop-cluster.sh
官方提供的两个 Flink 应用示例,可以很好地上手 Flink:
- 基于 DataStream API 实现欺诈检测:快速上手 State + Timer 流式处理;
- 基于 Table API 实现实时报表: 快速上手 Window 流式处理。
Flink 的一个重要特性就是其状态管理,Flink 为什么要参与状态管理?在 Flink 不参与管理状态的情况下,你的应用也可以使用状态,但 Flink 为其管理状态提供了一些引人注目的特性:
- 本地性: Flink 状态是存储在使用它的机器本地的,并且可以以内存访问速度来获取
- 持久性: Flink 状态是容错的,例如,它可以自动按一定的时间间隔产生 checkpoint,并且在任务失败后进行恢复
- 纵向可扩展性: Flink 状态可以存储在集成的 RocksDB 实例中,这种方式下可以通过增加本地磁盘来扩展空间
- 横向可扩展性: Flink 状态可以随着集群的扩缩容重新分布
Flink 的三个时间语义:
- Event Time:是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink 通过时间戳分配器访问事件时间戳。
- Ingestion Time:是数据进入 Flink 的时间。
- Processing Time:是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是 Processing Time。
Flink 在窗口的场景处理上很重要,窗口是基于 Timer 实现的。Flink 窗口操作将无界数据流分解成有界数据流聚合分析。Flink 内置窗口分配器如下:
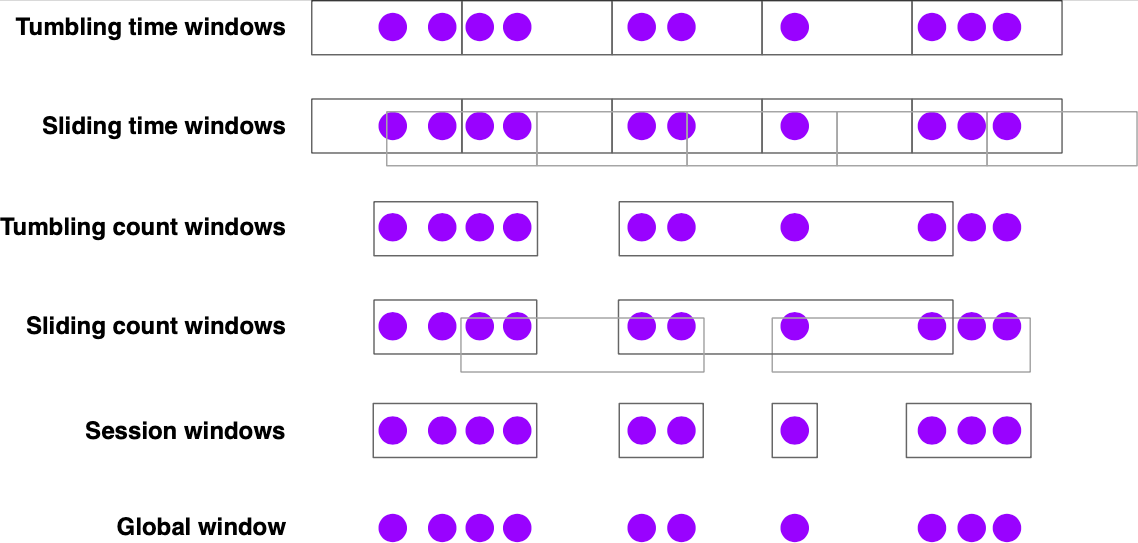
一些常见的对应使用场景:
- 滚动时间窗口:每分钟页面浏览量 -
TumblingEventTimeWindows.of(Time.minutes(1)) - 滑动时间窗口:每 10 秒钟计算前 1 分钟的页面浏览量 -
SlidingEventTimeWindows.of(Time.minutes(1), Time.seconds(10)) - 会话窗口:每个会话的网页浏览量,其中会话之间的间隔至少为 30 分钟 -
EventTimeSessionWindows.withGap(Time.minutes(30))
窗口操作的聚合类处理带来了新的问题,比如乱序/延迟。其解决方案就是 Watermark / allowLateNess / sideOutPut 这一组合拳。
- Watermark 定义了什么时候不再等待更早的数据,用于处理乱序事件;
- allowLateNess 是将窗口关闭时间再延迟一段时间,用于容忍迟到事件;
- sideOutPut 是最后兜底操作,当指定窗口已经彻底关闭后,就会把所有过期延迟数据放到侧输出流,让用户决定如何处理。
举个例子来理解上面这几个概念。假设我们需要通过 Flink 从 Kafka 消费数据,计算每五分钟的数据。
首先列出我们知道的事情。我们知道当前实际时间所处的窗口 [window_start, window_end],每条从 Kafka 来的数据都包含一个事件时间 event_time,我们可以设置 watermark 为 90s,从而每条数据对应的 watermark 时间就是 event_time - 90s,注意这个时间会确保 >= window_start 且左边界只会正增长。
- 当前窗口第一条数据出现,设事件时间为 last_event_time,计算得到当前窗口下一条数据的 event_time 范围
[last_event_time - 90s, window_end]; - 然后下一条数据到来,设事件时间为 event_time:
- 如果
last_event_time - 90s <= event_time <= window_end,则落入窗口,然后根据 watermark 计算新的 event_time 范围,重复 2; - 如果
event_time > window_end,则开启新窗口,完成旧窗口 window 聚合计算。如果 event_time - 90s <= window_end,则表明 watermark 未到,窗口保持开启,否则窗口延迟 allowLateNess 秒后关闭(不再聚合更多延迟数据)。重复 1,2; - 如果
event_time < last_event_time - 90s,则事件发生延迟,如果旧窗口还在则落入窗口并触发旧窗口 window 聚合计算,否则放到侧输出流,重复 2。
- 如果
可见,watermark 大大减少了聚合计算带来的开销,allowLateNess 在出现大量数据延迟的情况下则更有用。
最后记录一个 Task,计算每小时所有出租车司机中的最高总小费获得值,下面给出任务描述和关键代码:
The task of the exercise is to first calculate the total tips collected by each driver, hour by hour, and then from that stream, find the highest tip total in each hour.
1public JobExecutionResult execute() throws Exception {
2
3 // set up streaming execution environment
4 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
5
6 // start the data generator and arrange for watermarking
7 DataStream<TaxiFare> fares =
8 env.addSource(source)
9 .assignTimestampsAndWatermarks(
10 // taxi fares are in order
11 WatermarkStrategy.<TaxiFare>forMonotonousTimestamps()
12 .withTimestampAssigner(
13 (fare, t) -> fare.getEventTimeMillis()));
14
15 // compute tips per hour for each driver
16 DataStream<Tuple3<Long, Long, Float>> hourlyTips =
17 fares.keyBy((TaxiFare fare) -> fare.driverId)
18 .window(TumblingEventTimeWindows.of(Time.hours(1)))
19 .process(new AddTips());
20
21 // find the driver with the highest sum of tips for each hour
22 DataStream<Tuple3<Long, Long, Float>> hourlyMax =
23 hourlyTips.windowAll(TumblingEventTimeWindows.of(Time.hours(1))).maxBy(2);
24
25 hourlyMax.addSink(sink);
26 return env.execute("Hourly Tips");
27}
注意这里假定数据是有序的,所以采用了 WatermarkStrategy.<TaxiFare>forMonotonousTimestamps(),它将最大乱序程度设置为 0 毫秒,表示不允许有任何乱序。如果假定数据会乱序到达,则可以直接修改窗口 watermark 策略来完成。
最后可以了解一下处理函数(Process Functions)。ProcessFunction 将事件处理与 Timer,State 结合在一起,使其成为流处理应用的强大构建模块。使用 ProcessFunction 可以创建自定义的窗口操作。这里我们通过重写 KeyedProcessFunction 实现自定义窗口,使用 MapState + Timer 来处理数据,总体流程如下,具体参考flink-事件驱动应用:
- 设 MapState 的 key 为窗口的结束时间戳,值为该窗口的小费总和;
- 当窗口的第一个时间戳到达时,计算窗口结束时间戳,设置 MapState,注册回调 timer(回调时间可以设为 Watermark 到达窗口结束时间戳的实际时间);
- 后续时间戳到达,如果大于 Watermark 则 update MapState,否则为延迟事件;
- 一个小时过去,触发 Timer,计算结果,清除当前窗口的结束时间戳 kv;
- 重复 2~4。
更深入地了解 Flink:
State
State 泛指 Flink 中有状态函数和运算符在各个元素(element)/事件(event)的处理过程中存储的数据。状态数据可以修改和查询,可以自己维护,根据自己的业务场景,保存历史数据或者中间结果到 State 中。
使用状态计算的例子:
- 当应用程序搜索某些事件模式时,状态将存储到目前为止遇到的事件序列。
- 在每分钟/小时/天聚合事件时,状态保存待处理的聚合。
- 当在数据点流上训练机器学习模型时,状态保持模型参数的当前版本。
- 当需要管理历史数据时,状态允许有效访问过去发生的事件。
无状态计算指的是数据进入 Flink 后经过算子时只需要对当前数据进行处理就能得到想要的结果;有状态计算就是需要和历史的一些状态或进行相关操作,才能计算出正确的结果。
Checkpoint 机制
Flink 是有状态的流计算处理引擎,每个算子 Operator 可能都需要记录自己的运行数据,并在接收到新流入的元素后不断更新自己的状态数据。当分布式系统引入状态计算后,为了保证计算结果的正确性(特别是对于流处理系统,不可能每次系统故障后都从头开始计算),就必然要求系统具有容错性。
Checkpoint 机制是 Flink 容错性、可靠性的基石,可以保证 Flink 集群在某个算子因为某些原因(如异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某 一状态,保证应用流图状态的一致性。
Barrier 是 Flink 分布式快照的核心概念之一,称之为屏障或者数据栅栏(可以理解为快照的分界线)。Barrier 是一种特殊的内部消息,在进行 Checkpoint 的时候 Flink 会在数据流源头处周期性地注入 Barrier,这些 Barrier 会作为数据流的一部分,一起流向下游节点并且不影响正常的数据流。Barrier 的作用是将无界数据流从时间上切分成多个窗口,每个窗口对应一系列连续的快照中的一个,每个 Barrier 都带有一个快照 ID,一个 Barrier 生成之后,在这之前的数据都进入此快照,在这之后的数据则进入下一个快照。
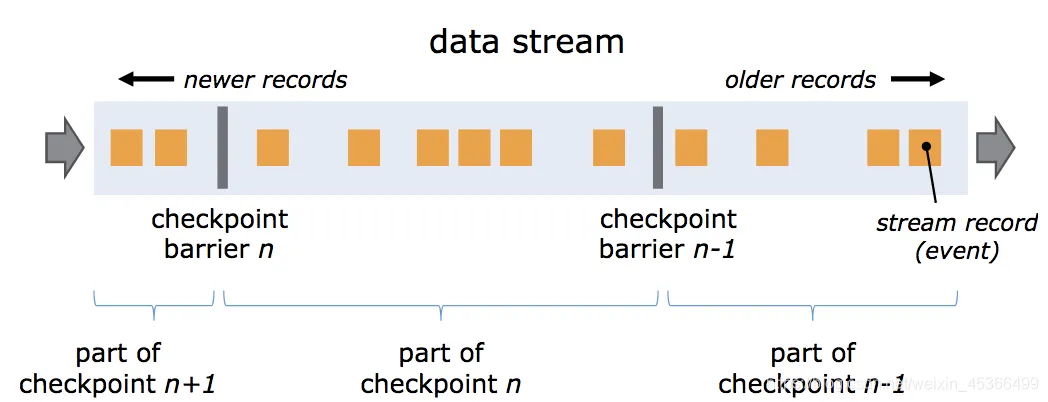
每个需要 checkpoint 的应用在启动时,Flink 的 JobManager 为其创建一个 Checkpoint Coordinator,Checkpoint Coordinator 全权负责本应用的快照制作。如上图,Barrier-n 跟随着数据流一起流动,当算子从输入流接收到 Barrier-n 后,就会停止接收数据并对当前自身的状态做一次快照,快照完成后再将 Barrier-n 以广播的形式传给下游节点。一旦作业的 Sink 算子接收到 Barrier-n 后,会向 JobMnager 发送一个消息,确认 Barrier-n 对应的快照完成。当作业中的所有 Sink 算子都确认后,意味一次全局快照也就完成。
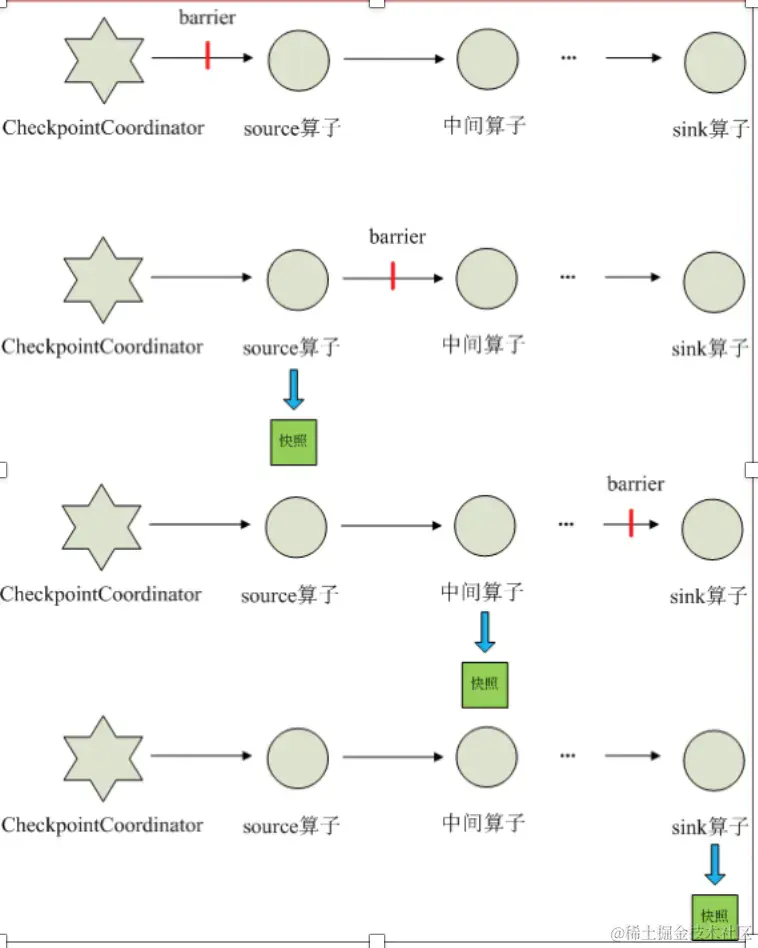
当一个算子有多个上游节点时,会接收到多个 Barrier,这时候需要进行 Barrier Align 对齐操作。假设一个算子有两个输入流,当算子从一个上游数据流接收到一个 Barrier-n 后,它不会立即向下游广播,而是先暂停对该数据流的处理,将到达的数据先缓存在 Input Buffer 中(因为这些数据属于下一次快照而不是当前快照,缓存数据可以不阻塞该数据流),直到从另外一个数据流中接收到 Barrier-n,才会进行快照处理并将 Barrier-n 向下游发送。
综上,Flink Checkpoint 机制的核心思想实质上是通过 Barrier 来标记触发快照的时间点和对应需要进行快照的数据集,将数据流处理和快照操作解耦开来,从而最大程度降低快照对系统性能的影响。
一致性
Flink 的一致性和 Checkpoint 机制有紧密的关系:
- 当不开启 Checkpoint 时,节点发生故障时可能会导致数据丢失,这就是 At-Most-Once
- 当开启 Checkpoint 但不进行 Barrier 对齐时,对于有多个输入流的节点如果发生故障,会导致有一部分数据可能会被处理多次,这就是 At-Least-Once
- 当开启 Checkpoint 并进行 Barrier 对齐时,可以保证每条数据在故障恢复时只会被重放一次,这就是 Exactly-Once
并行度
一个 Flink 程序由多个任务 task 组成(转换/算子、数据源和数据接收器)。一个 task 包括多个并行执行的实例,且每一个实例都处理 task 输入数据的一个子集。一个 task 的并行实例数被称为该 task 的 并行度 (parallelism)。
Flink 提供了多种方式来设置并行度:
- 全局并行度: 在执行环境中设置,影响所有算子的并行度。
- 算子级别并行度: 为每个算子单独设置并行度。
- 客户端级别并行度: 在提交作业时设置并行度。
并行度和 Slot:
Slot(槽)是一个非常重要的概念,它代表了 TaskManager 上的一份固定大小的资源,一个 TaskManager 可以有多个 slot。一个 slot 可以执行一个或多个子任务,一个slot上有多个子任务时,这些子任务会共享该slot的资源。如果一个算子的并行度大于 slot 的数量,那么多个子任务会竞争 slot 资源。
反压机制
Flink 的反压策略主要分为以下几个步骤:
- 任务反压:当下游任务的处理速度较慢时,Flink 会检测到这种情况,并认为这是一个反压信号。此时,Flink 会将这个反压信号传递给上游任务的管理器。
- 调整数据生成速度:当上游任务的管理器收到反压信号后,会根据反压信号的强度来调整数据生成速度。通常情况下,反压信号越强,上游任务生成的数据量就会减少,以减轻下游任务的负担。
- 控制反压:Flink 还会通过一些控制机制来避免过度反压。例如,当上游任务的数据生成速度过慢时,Flink 会限制反压的强度,以避免数据积压过多。此外,Flink 还会设置一个反压阈值,当反压信号超过这个阈值时,Flink 会认为任务已经处于一个不稳定的状态,并会采取相应的措施,如调整任务并行度、暂停任务等。
- 恢复数据生成速度:当下游任务的处理速度恢复到正常水平时,Flink 会检测到这个变化,并逐渐增加上游任务的数据生成速度,以恢复数据流。
三种时间语义
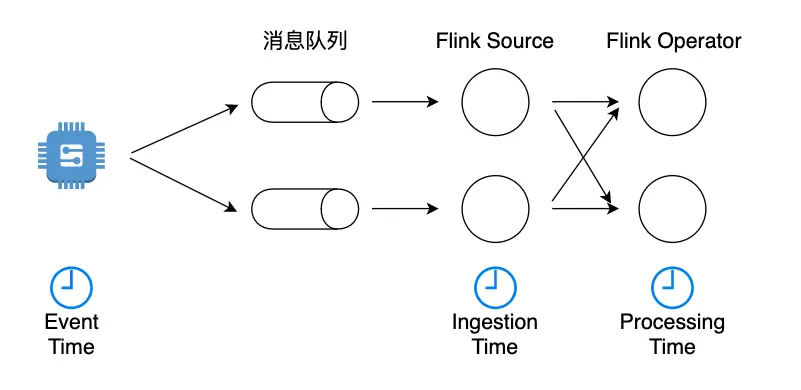
Event Time 指的是数据流中每个元素或者每个事件自带的时间属性,一般是事件发生的时间。由于事件从发生到进入 Flink 时间算子之间有很多环节,一个较早发生的事件因为延迟可能较晚到达,因此使用 Event Time 意味着事件到达有可能是乱序的,所以使用 Watermark 通常是有必要的。
Ingestion Time 是事件到达 Flink Souce 的时间。从 Source 到下游各个算子中间可能有很多计算环节,任何一个算子的处理速度快慢可能影响到下游算子的 Processing Time。而 Ingestion Time 定义的是数据流最早进入 Flink 的时间,因此不会被算子处理速度影响。
LSM

LSM tree, short for Log-Structured-Merge Tree, is a clever algorithm design that helps us store massive amounts of data without making us wait forever to write it. It stores data in memory first, which is lightning fast. But since we can’t keep everything in memory, the LSM Tree periodically flushes data to disk.
But here’s where it gets even cooler! It organizes the data into layers of sorted structures, each with more and more compressed data. The top layer is the fastest to access but the least compressed. As the data piles up, it’s compressed and written into a new layer called an SSTable (Sorted String Table). We can decide how many layers we need and how much compression to apply, based on the type of data we’re dealing with. This trick helps us minimize disk I/O operations and make our data storage super efficient!
WRITE:
- The data is first written to the in-memory layer for speedy performance.
- Simultaneously, the changes are recorded in the Write-Ahead Log to ensure data integrity.
- Then, at regular intervals or when the in-memory layer reaches a certain threshold, the data is flushed to disk and organized into SSTables.
READ:
- Check the data at in-memory layer
- Check the bloom filter that indicates whether the data might exist in a specific SSTable
- Search the specified SSTable at on-disk layer
Kafka
Apache Kafka 是一个分布式的流处理平台。我所知的 Kafka 通常是作为一个消息队列的角色而存在的,在 Shopee 的大数据处理架构中,Kafka 作为 MySQL 和大数据处理框架之间的一个桥梁。 Kafka 订阅了 Binlog,产生一些列消息,让大数据处理框架进行消费。
TODO:之后会记录一些 Kafka 的原理知识和相关代码实践。
Hive
Hive 是一个构建在 Hadoop 之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类 SQL 查询功能,用于查询的 SQL 语句会被转化为 MapReduce 作业,然后提交到 Hadoop 上运行。Hive 架构如下:
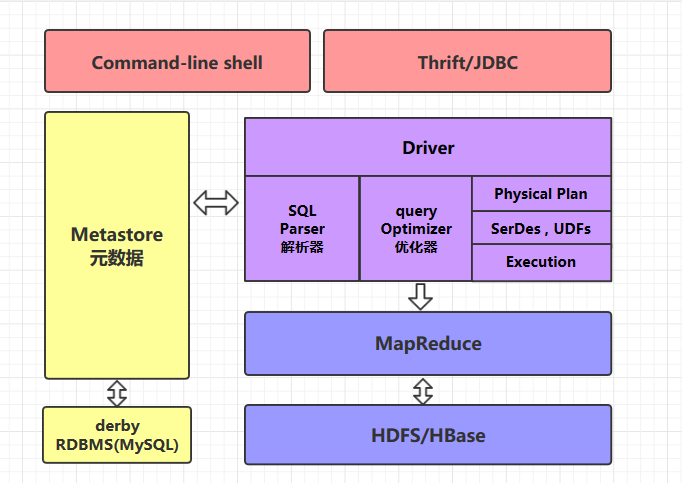
Hive 由内部表和外部表的概念,在导入数据到内部表,内部表数据的生命周期由 Hive 来进行管理,存在自己的数据仓库目录下。 而外部表只是在元数据中存储了数据的位置。
Hive 中有分区和分桶的概念,每个表可以有一个或多个分区键,用于确定数据的存储方式。 分区键的每个唯一值定义了表的一个分区。每个分区中的数据又可以基于表的某一列的散列函数的值被划分为桶。
接下来我着重记录了 HiveSQL 相关知识。
HiveSQL 在排序这一块与传统 SQL 有较大差别:
- order by 是全局排序,可能性能会比较差;
- sort by 进行分区内排序,往往配合 distribute by 来确定该分区都有那些数据;
- distribute by 确定了数据分发的规则,满足相同条件的数据被分发到一个reducer;
- cluster by 当 distribute by 和 sort by 字段相同时,可以使用 cluster by 代替 distribute by 和 sort by;
- sort by limit 相当于每个 reduce 的数据 limit 之后,进行 order by 然后再 limit。
HiveSQL 支持 WITH AS 临时中间表,当我们书写一些结构相对复杂的 SQL 语句时,可能某个子查询在多个层级多个地方存在重复使用的情况,这个时候我们可以使用 WITH AS 语句将其独立出来,极大提高SQL可读性,简化 SQL。
1-- with table_name as(子查询语句) 其他sql
2WITH t1 AS (
3 SELECT *
4 FROM abc
5 ),
6 t2 AS (
7 SELECT *
8 FROM efg
9 )
10SELECT *
11FROM t1, t2;
12-- 如果定义了 with 子句,但其后没有跟 select 查询,则会报错(没有使用没关系,其后必须有 select),因此不允许单独使用。
HiveSQL 支持窗口计算。在 Hive 中,窗口函数允许你在结果集的行上进行计算,这些计算不会影响你查询的结果集的行数。
Hive 提供的窗口和分析函数可以分为聚合函数类窗口函数,分组排序类窗口函数,偏移量计算类窗口函数。语法如下:
1-- 分析函数
2over(partition by 列名 order by 列名 rows between 开始位置 and 结束位置)
3
4-- 聚合函数类
5count() over();
6sum() over();
7max() over();
8min() over();
9avg() over();
10
11-- 分组排序类
12row_number() over(); -- 按照排序的顺序输出窗口中的数据的行号信息
13rank() over(); -- 按照指定列进行排名,如果值相同,则排名并列,下一个排名会出现跳跃,即排名是不连续的
14dense_rank() over(); -- 相比 rank() 不会跳跃
15percent_rank() over(); -- 按百分比进行排名
16cume_dist() over(); -- 如果按升序排列,则统计:小于等于当前值的行数所占当前分区窗口总行数的比例。如果是降序排列,则统计:大于等于当前值的行数所占当前分区窗口总行数的比例
17ntile() over(); -- 用于将按指定列分组的数据按照顺序切分成 N 片,返回当前切片值
18
19-- 求偏移量类
20lead() over(); -- 用于统计窗口内往下第 n 行值
21lag() over(); -- 用于统计窗口内往上第 n 行值
22first_value() over(); -- 取分组内排序后,截止到当前行,第一个值
23last_value() over(); -- 取分组内排序后,截止到当前行,最后一个值
over()括号内为空时,是直接进行聚合计算。- 其中
partition by列名 是按指定列进行分组,进而进行聚合计算。 - 最后的
order by列名 是按照指定列进行排序,进而进行聚合计算。
具体用例参考这篇文章,特别详细,比如:
1-- 按照星座分组,统计出 pv 由高到低的排名。
2select
3id, client, gender,
4row_number() over(partition by constellation order by pv desc) as rank_id
5from temp.user_info where id <= 10;
6
7
8-- 统计小于等于当前年龄的人数占总人数的比例。
9select id, client, age,
10cume_dist() over(order by age desc) as rank_id
11from temp.user_info where id <= 10
12order by age;
HBase
HBase 是一个面向列式存储的分布式数据库,其设计思想来源于 Google 的 BigTable 论文。HBase 底层存储基于 HDFS 实现,集群的管理基于 ZooKeeper 实现。
HBase 良好的分布式架构设计为海量数据的快速存储、随机访问提供了可能,基于数据副本机制和分区机制可以轻松实现在线扩容、缩容和数据容灾,是大数据领域中 Key-Value 数据结构存储最常用的数据库方案。
HBase 的数据模型:
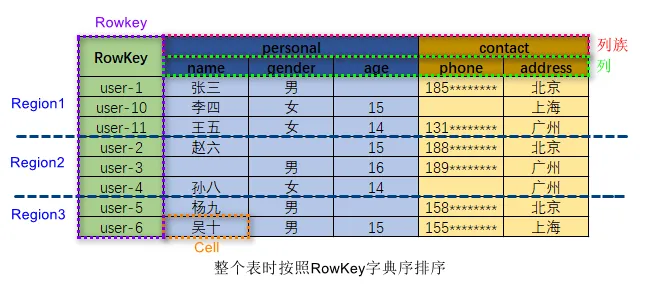
在 HBase 表中,一条数据拥有一个全局唯一的键(RowKey)和任意数量的列(Column),一列或多列组成一个列族(Column Family),同一个列族中列的数据在物理上都存储在同一个 HFile 中,这样基于列存储的数据结构有利于数据缓存和查询。
HBase 中的表是疏松地存储的,因此用户可以动态地为数据定义各种不同的列。HBase 中的数据按主键排序,同时,HBase 会将表按主键划分为多个 Region 存储在不同 Region Server 上,以完成数据的分布式存储和读取。
HBase 根据列成来存储数据,一个列族对应物理存储上的一个 HFile,列族包含多列列族在创建表的时候被指定。
通过几条操作语句了解 HBase 数据模型:
1# hbase shell
2# create '表名称', '列族名称1', '列族名称2', '列族名称N'
3create 'users', 'sex', 'info'
4# put '表名称','行名称','列族名称(:列名称)', '列值'
5put 'users', 'jack', 'sex', 'male'
6put 'users', 'jack', 'info:age', '20'
Paimon
为什么要有 Paimon?在最近开发 Shopee 订单关键指标的过程中,通过当前整个大数据计算框架,我大致明白了,具体记录如下。
首先,目前基于 Hadoop 的大数据计算体系中,如果单纯的基于 hdfs 进行 mp 计算,比如 hive,则只能实现 insert 或 insert overwrite,只能去计算 T+1 级别的数据,在计算 Shopee 订单关键指标时,就常常被用于计算一天内的订单量、成交额,这个是可以确保准确且稳定的。
还是在 Hadoop 体系内,我们希望去计算更实时的数据,比如小时、分钟级别的,可能会去采用 hudi,因为 hudi 支持 upsert。hudi upsert 支持 mor 和 cow 两种模式,而一般采用的 cow 模式 cpu 占用率较高,根据 Shopee 实际情况,hudi 常常顶不住超大数据+复杂跨国链路的压力,加上带宽相关的限制,其他团队常常反馈数据延迟过高,通过 hudi 计算小时级别的数据常常不可靠,分钟级别的就更不必说了。目前,团队将向 paimon 迁移,后文继续说明。
如果跳出 Hadoop 体系,那就是使用 flink 去计算实时数据,官方说是支持 ms 级别,但在超大数据复杂链路的情况下,一般是 s 级别,在计算 Shopee 订单关键指标时,我们采用 flink 来计算分钟级别的数据。只是在有些情况下,flink 可能不够稳定,需要加 dqc,通过离线数据去对账更新实时的数据。
为更好地计算小时级别的数据,可以说是 T+0 数据(而一般 3-5 小时到 1 天级别的数据称为 T+1 数据),也就是更低延迟、更低成本地去计算更细粒度时间级别的数据,目前 Paimon 是一种可能的解决方案。
Apache Paimon 是一个湖格式,结合 Flink 及 Spark 构建流批处理的实时湖仓一体架构。Paimon 创新的结合湖格式与 LSM 技术,给数据湖带来了实时流更新以及完整的流处理能力。通常的实现方式是采用 Flink 实时计算相关数据写入 Paimon,这样利用了 Flink 的低延迟特性,也实现了对 hdfs 的 upsert 操作。
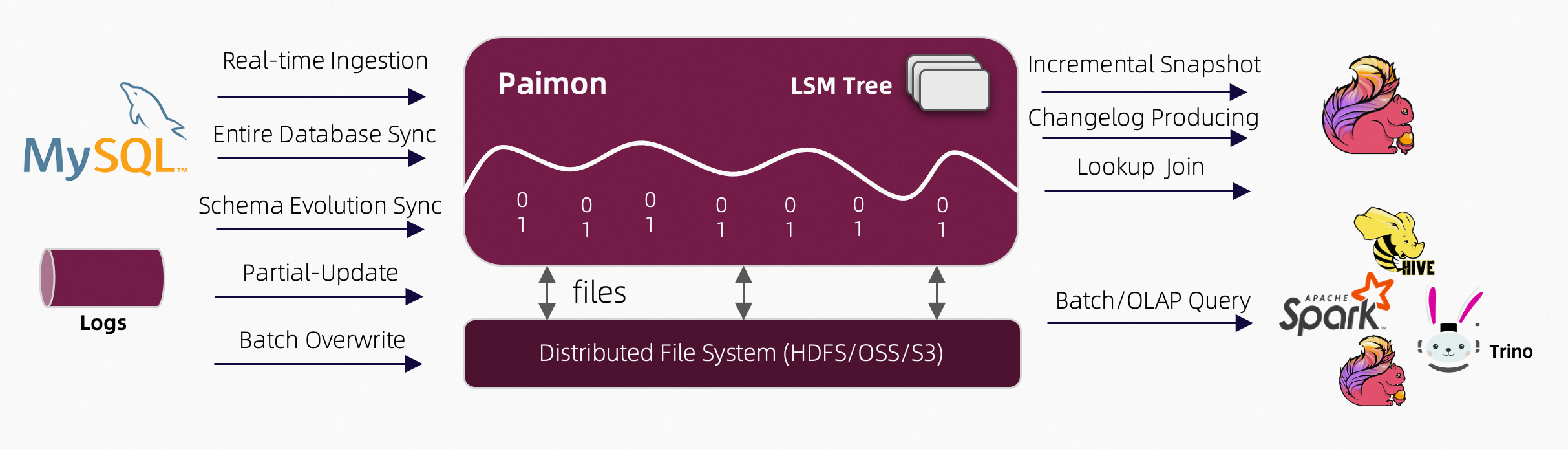
Paimon 是当今大数据前沿技术,这里有具体用法入门:Paimon 快速开始:基本功能
后续会在项目中对 Paimon 进行具体实践,到时将技术设计同步到此处。
Hudi
Hudi(Hadoop Upserts Deletes and Incrementals)是一个用于跟踪大规模数据集的变化的数据管理库。
Hudi 通过提供增量数据存储和查询能力,支持数据的插入、更新和删除操作。Hudi 还提供了时间旅行功能,可以让用户查询数据在不同时间点的快照。
Hudi 适用于数据湖、实时分析和流处理场景。
和 Hive 的区别:
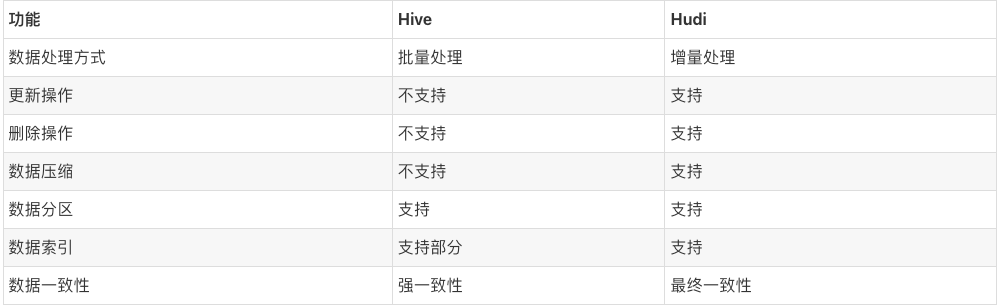
ClickHouse
TODO
MPP
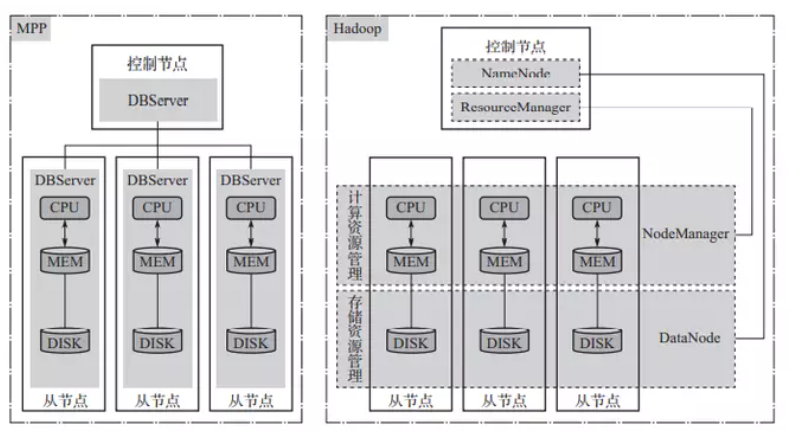
MPP(Massively Parallel Processing)架构数据库是一种分布式数据库架构,它将数据分布到多个节点上,并利用这些节点的计算资源并行处理数据。MPP 数据库通常用于处理大规模数据集,能够提供更高的性能和扩展性。MPP 常见的应用场景包括数据分析、实时报表、数据仓库等。
MPP 架构数据库通常由多个节点组成,每个节点都具有独立的计算资源和存储空间。数据被分区存储在不同的节点上,每个节点负责处理自己所存储的数据。当进行查询时,MPP 数据库可以并行处理多个节点上的数据,从而提高查询性能。
MPP 应该与 Hadoop 进行比较,mpp 相当于找一群和自己能力差不多的任一起做事,每个人做的事情是一致的。而 Hadoop 就是找一群能力差一些的人,但只需要他们每个人只做一部分工作。
StarRocks
StarRocks 采用 MPP (Massively Parallel Processing) 分布式执行框架。
在 MPP 执行框架中,一条查询请求会被拆分成多个物理计算单元,在多机并行执行。每个执行节点拥有独享的资源(CPU、内存)。MPP 执行框架能够使得单个查询请求可以充分利用所有执行节点的资源,所以单个查询的性能可以随着集群的水平扩展而不断提升。
BitMap
Bit 即比特,是目前计算机系统里数据的最小单位。BitMap 可以理解为通过一个 bit 数组来存储特定数据的一种数据结构,由于 bit 是数据的最小单位,所以这种数据结构往往是非常节省存储空间。
比如一个公司有 8 个员工,现在需要记录公司的考勤记录,可以构造一个 8bit 的数组,将这 8 个员工跟员工号分别映射到这 8 个位置,如果当天正常考勤了,则将对应的这个位置置为 1,否则置为 0,这样可以每天采用恒定的 1 个byte即可保存当天的考勤记录,大量节省了存储空间。
除了节省存储空间,BitMap 结构的另一个更重要的特点,就是很方便通过位的运算(AND,OR,XOR,NOT),高效的对多个 BitMap 数据进行处理。比如上边的考勤的例子里,如果想知道那个员工最近两天都没来,只要将昨天的 BitMap 和今天的 BitMap 做一个按位的 OR 计算,然后检查那些位置是 0,就可以得到最近两天都没来的员工的数据了。
Blogs
- 时间与精神的小屋
- 阿里 E-MapReduce
- Shopee 技术团队(微信公众号)
Reference
- Apache Flink 官方文档
- heibaiying/BigData-Notes
- Apache Spark 官方文档
- Spark 第三方中文文档
- Kafka 官方文档
- Kafka 第三方中文文档
- Google Cloud - Hadoop
- [白话解析] Flink 的 Watermark 机制
- apache/flink-training
- 美团外卖实时数仓建设实践
- 阿里开源大数据平台 - Paimon
- Apache Paimon 官方文档
- 当流计算邂逅数据湖:Paimon 的前生今世
- Hive SQL 教程
- Hive 中的四种排序详解,再也不会混淆用法了。
- Flink Checkpoint 机制详解
- Flink 基础教程:时间语义、Event Time 和 Watermark 机制原理与实践
- LSM Trees: the Go-To Data Structure for Databases, Search Engines, and More